왜 날짜(date type)를 DB에 저장할때 INT형으로 저장했을까?
- Study/IT 실전 지식
- 2021. 8. 1. 04:14
처음 증권회사에 들어가서 DB에 있는 데이터를 봤을 때 신기했던 점이 있었다. 날짜와 시간이 INT형으로 되어있던 부분이다. DATE 필드는 20150909의 숫자형으로 저장되어있었고 시간 역시 153030으로 시, 분, 초의 값이 숫자형으로 되어있었다. 그래서 오전 9시를 저장하면 90000이 돼서 5자리고 오후가 넘어가면 120000이 되어 6자리가 되는 보기에 이상한 데이터가 되어버렸다.
그때는 그저 숫자로 하면 소스에서 비교가 쉽기 때문에 그랬나 보다~라고 생각했다. 증권사에서는 주식의 시세 데이터를 다루기 때문에 시간으로 비교를 하는 경우가 매우 많다. 차트를 그릴 때도, 현재가를 알려줄 때도 항상 기준은 날짜와 시간이다.
최근에 '동기부여'라는 타이머앱을 만들면서 서버에 시간별 공부 데이터를 저장하고 있다. django 플랫폼을 이용한 ORM형태로 만들었기 때문에 공부한 시간 model을 만들 때 시간은 datetime type을 사용했다. datetime type을 사용하면 좋은 점은, 소스에서 연도, 월, 일 등을 쉽게 계산할 수 있다는 점이다. 그렇게 반년 정도 운영을 하고 나서, 사용자의 전체 공부 데이터를 리포팅해주는 API의 속도가 점점 느려지는 점을 발견했다.
초반에 쿼리를 잘못짠게 아닐까?라는 생각에 API를 하나하나 뜯어보면서 어디가 느린지 디버깅해보았다. django에서는 queryset이라는 객체 기반의 함수를 사용해 쿼리를 만들고, 실제로 데이터를 호출할 때 쿼리가 실행된다. 따라서 코드상에서는 쿼리를 알 수가 없지만, print(queryset.query)를 통해 어떤 쿼리가 실제로 실행되는지 알 수 있다.
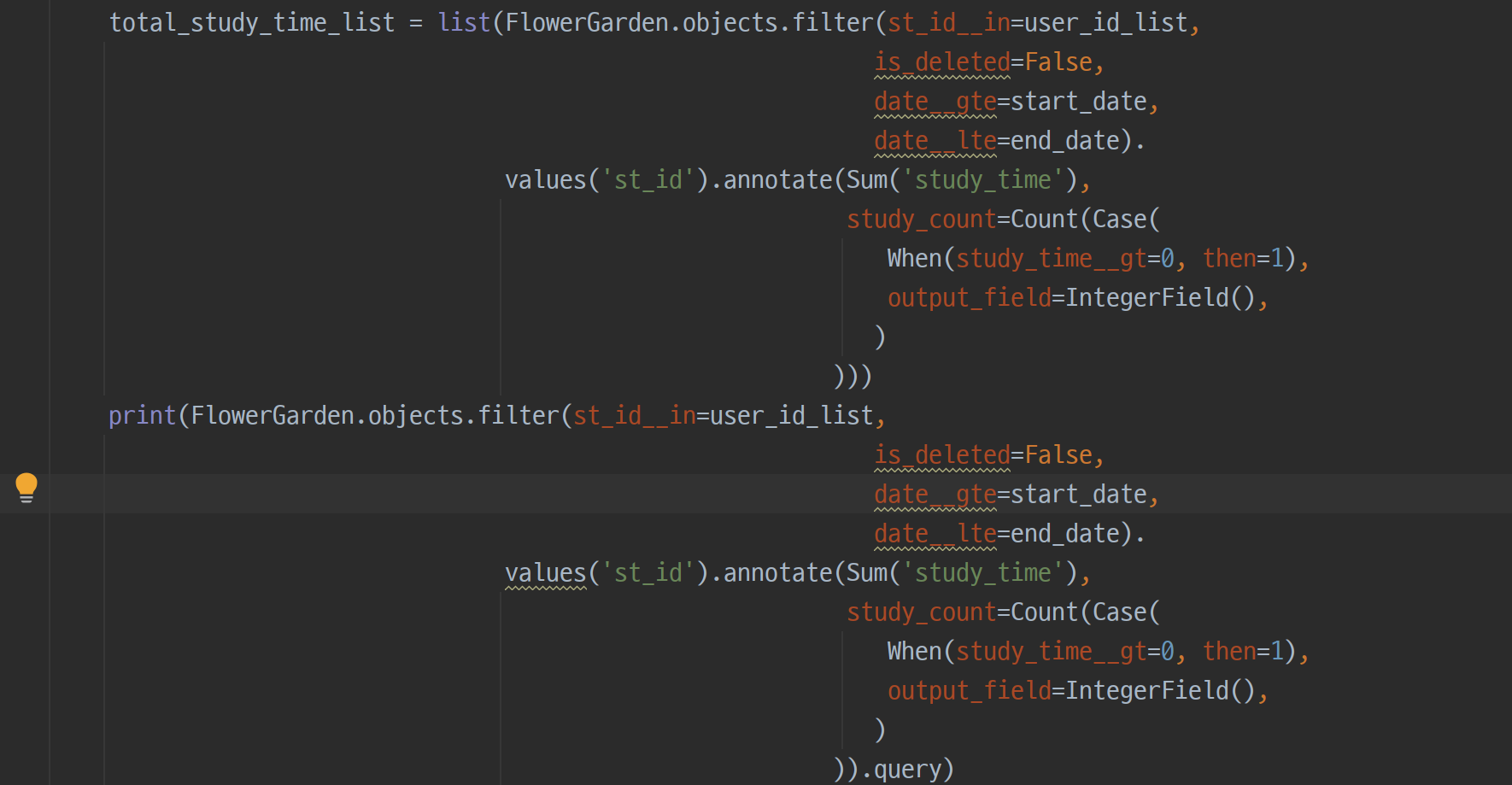
이렇게 출력해본 쿼리에 대해 Query Plan을 실행시켜 보면 쿼리가 어떻게 실행되는지 분석할 수 있다.

내가 사용하고 있는 툴 datagrip에서는 Alt + P를 누르면 해당 쿼리의 플랜을 볼 수 있다. 플랜을 보면 이 쿼리가 어떤 인덱스를 타고 어떤 순서로 실행되는지 알 수 있는데, 위 사진에서 보면 'Full scan(ALL)'로 찍혀있는 게 보인다. 이건 쿼리가 인덱스를 타지 않고 전체 테이블 검색을 한다는 뜻으로 데이터가 많으면 많아질수록 상당히 느린 쿼리가 된다.
이렇게 쿼리가 어떻게 실행되는지 확인하고, 느린 부분에 대해 인덱스를 잡는것이 쿼리 개선 작업이다. 해당 플랜을 보고 date 필드에 대한 인덱스가 안 잡혀있는지 확인해보았다.

어랏.. date가 확실히 인덱스에 잡혀있다. 그런데 왜? 인덱스를 타지 않고 Full Scan을 하는 것일까?
구글링 해본 결과 mysql에서 date타입에 대한 where 조건일 경우, 인덱스를 타지 않는다고 한다. 단순히 단건 조회일경우 인덱스를 먹지만 기간으로 비교할 경우 인덱스를 사용할 수 없는 것 같다. 흐미..
이래서 날짜를 INT로 했구나!!
처음부터 날짜를 INT로 저장했다면 인덱스가 먹어서 속도가 매우 빨라졌을 것이다. 하지만 날짜비교를 하는 서비스가 생길지 몰랐고, date type이 인덱스 안 먹는지도 몰랐기 때문에 이제 와서 바꾸는 건 매우 큰 작업이 될 것 같다.
회사에서 왜 날짜와 시간을 숫자로 쓰는지 깨닫고, 초기 DB 스키마 구축이 중요하다는 것을 뼈저리게 느낀 사건이었다.
담부터는 날짜는 왠만하면 INT로 하자 ㅎㅎ
'Study > IT 실전 지식' 카테고리의 다른 글
| UI/UX light-mode, dark-mode를 넘어선 Gen-z 모드ㅋㅋㅋㅋ (2) | 2022.03.17 |
|---|---|
| CI에서 db 속도 향상. mysql tmpfs 사용하기 (1) | 2022.03.11 |
| 개발자라면 지금 클럽하우스에서 이런 정보들 들으세요!! (1) | 2021.02.11 |
| 혼자 일정관리하기 좋고, 같이 쓰면 더 좋은 생산성 툴 젯브레인 스페이스 (jetbrain space) (2) | 2021.02.02 |
| 15분 지연 프로그램 만들기 (0) | 2019.06.19 |