[개발자의 시선으로 보는 머신러닝 2-1편] 랜덤 포레스트로 예측, 분류 한번씩 해보기
- Study/AI
- 2020. 7. 13. 00:57
들어가기 전에
지난 포스팅에서 의사결정나무와 랜덤포레스트를 이용한 분류 모델을 만들었습니다.
트리 형태의 머신러닝 모델이 분류에서만 사용될 것 같이 보이나 예측에도 충분히 사용될 수 있다는 사실!
데이터의 특성에 따라 어떨 때는 타 모델보다 높은 성능을 보여줄 때도 있습니다.
이번 포스팅에서는 실제 사용되는 데이터를 가지고 랜덤포레스트 모델을 활용한 예측 및 분류를 해볼 텐데요.
더미 데이터가 아니라 실제 데이터이기 때문에 업무에서 머신러닝이 어떻게 사용될 수 있는지 알아볼 수 있는 기회가 될 수 있으면 좋겠습니다.
데이터 살펴보기
AI 업무를 할 때 가장 중요한 데이터를 먼저 살펴보겠습니다.
데이터와 소스는 github에 올려놨습니다.
https://github.com/tkdlek11112/AI_by_dev -> 랜덤포레스트를 이용한 예측 및 분류 폴더

이 데이터는 자산관리 어플을 사용하는 사용자의 데이터입니다. 컬럼을 하나하나 살펴볼까요?
user_id : 사용자 고유 ID값
gender : 성별
age : 나이
os : 사용하는 모바일 OS
portfolio_type : 이용중인 포트폴리오 타입
annual_income : 연봉
initial_date : 투자 시작일
initial_amount : 시작 금액
add_amount : 추가 금액
prior_investment : 투자경험
etf_knowledge : ETF 지식
occupation : 직업
total_asset : 총 자산
target_period : 투자기간
investment_priority : 투자우선순위
patience_to_loss_percentage : 위험감내도
investment_amount : 투자희망금액
add_count : 추가투자 횟수
total_amount : 총 투자금액
target_count : 추가투자여부
자 우리에게 자산관리 어플을 사용하는 만 명의 정보가 있습니다. 이 데이터로 무엇을 할 수 있을까요?
우선 자산관리에 제일 중요해 보이는 총 투자금액(total_amount)이 보입니다. 사용자의 성별이나 나이, 연봉으로 총 투자금액을 예측할 수 있지 않을까요?
아니면 추가 금액(add amount), 추가 투자 횟수(add count)를 예측할 수 있다면 추가 투자를 할 것 같은 사용자에게 공격적인 마케팅을 할 수 있지 않을까요?
이런 식으로 데이터를 이용해 의사결정을 도와주는 직군이 데이터 분석가입니다. 회사 성장에 꼭 필요한 직군이죠.
저희는 이번 포스팅에서 사용자 정보에 따라 총 투자금액을 예측할 수 있을지, 추가 투자를 할 고객인지 안 할 고객인지 분류해보는 작업을 해보도록 하겠습니다.
데이터 전처리
이전 포스팅에서 범주형 데이터에 대해 완벽히 이해하신 분이면, 데이터를 보고
"왜 이렇게 처리할 게 많아?"
라고 하셨을 거예요. 사용자의 정보 대부분이 범주형 데이터로 되어있습니다.
예를 들면 target_preiod는 투자기간으로 [1 - 1년 이하], [2 - 1~3년], [3 - 3년 이상]으로 구분되어 있습니다. 따라서 전처리를 아주 아주 아주~ 더럽게 해야 돼요.
일단 colab을 실행합니다. colab 파일 역시 github에 있기 때문에 다운로드하여서 사용하세요~!
https://github.com/tkdlek11112/AI_by_dev -> 랜덤포레스트를 이용한 예측 및 분류 폴더
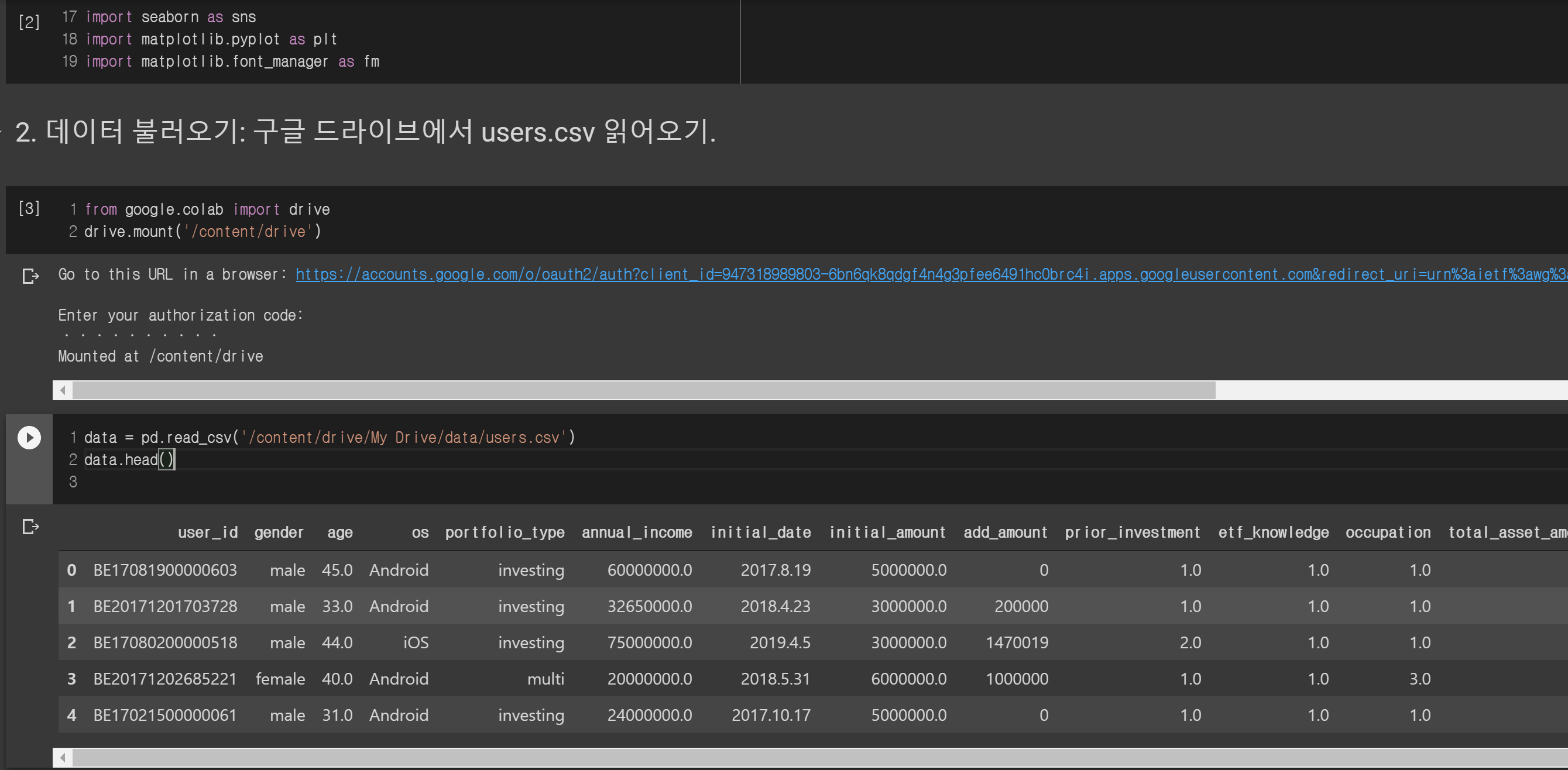
일단 기본적인 패키지를 불러오고 구글 드라이브에 users.csv를 업로드 한 다음 colab에서 읽어봅시다. data.head()를 통해 상위 데이터를 출력해보고요.
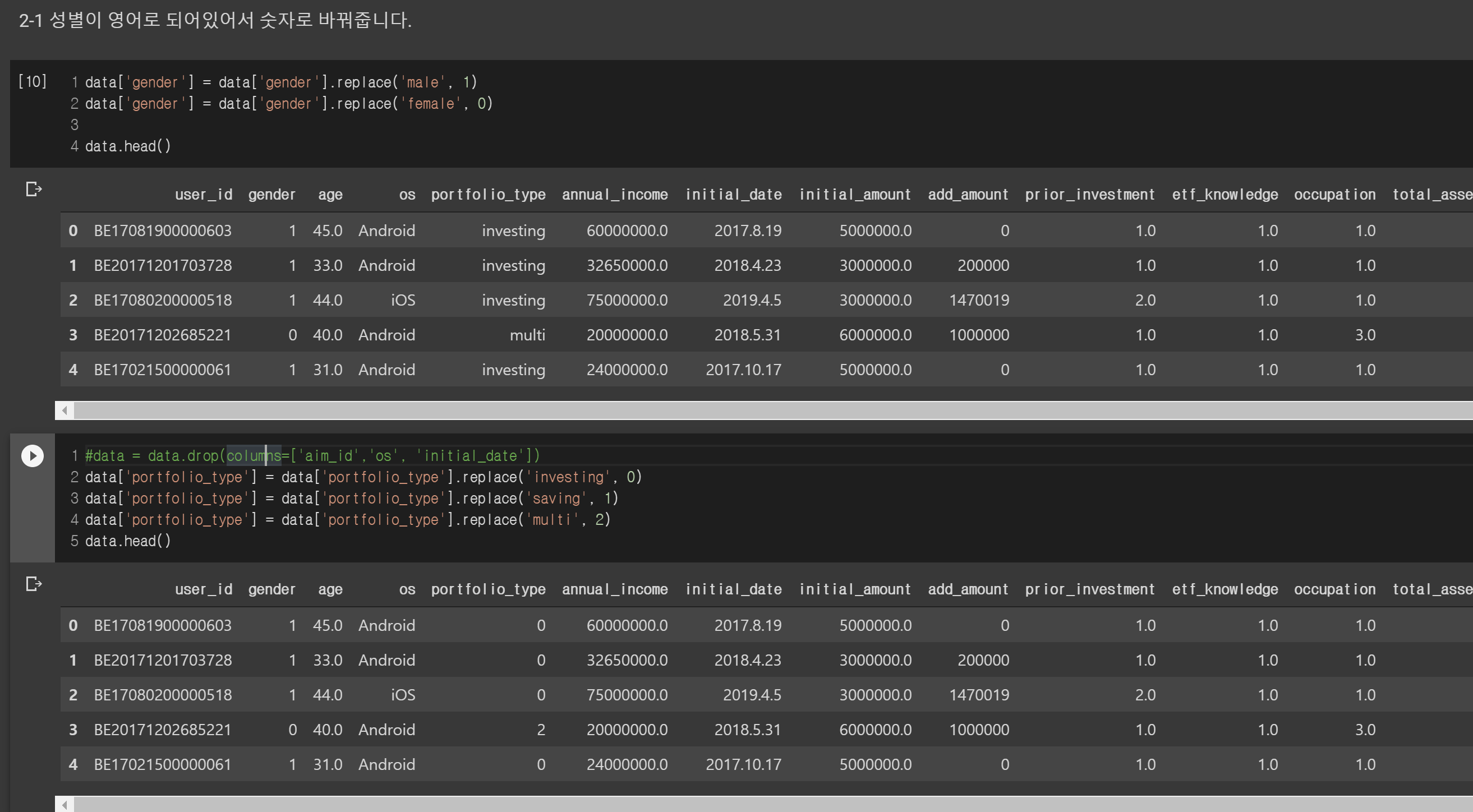
그다음은 영어로 저장되어있는 정보를 숫자로 바꿉니다. 성별과 포트폴리오 종류가 문자열로 되어있는데 각각 숫자로 구분해줍니다.
os도 영어로 되어있기는 한데 나중에 데이터에서 제외할 거라서 하지 않습니다 ㅎㅎ
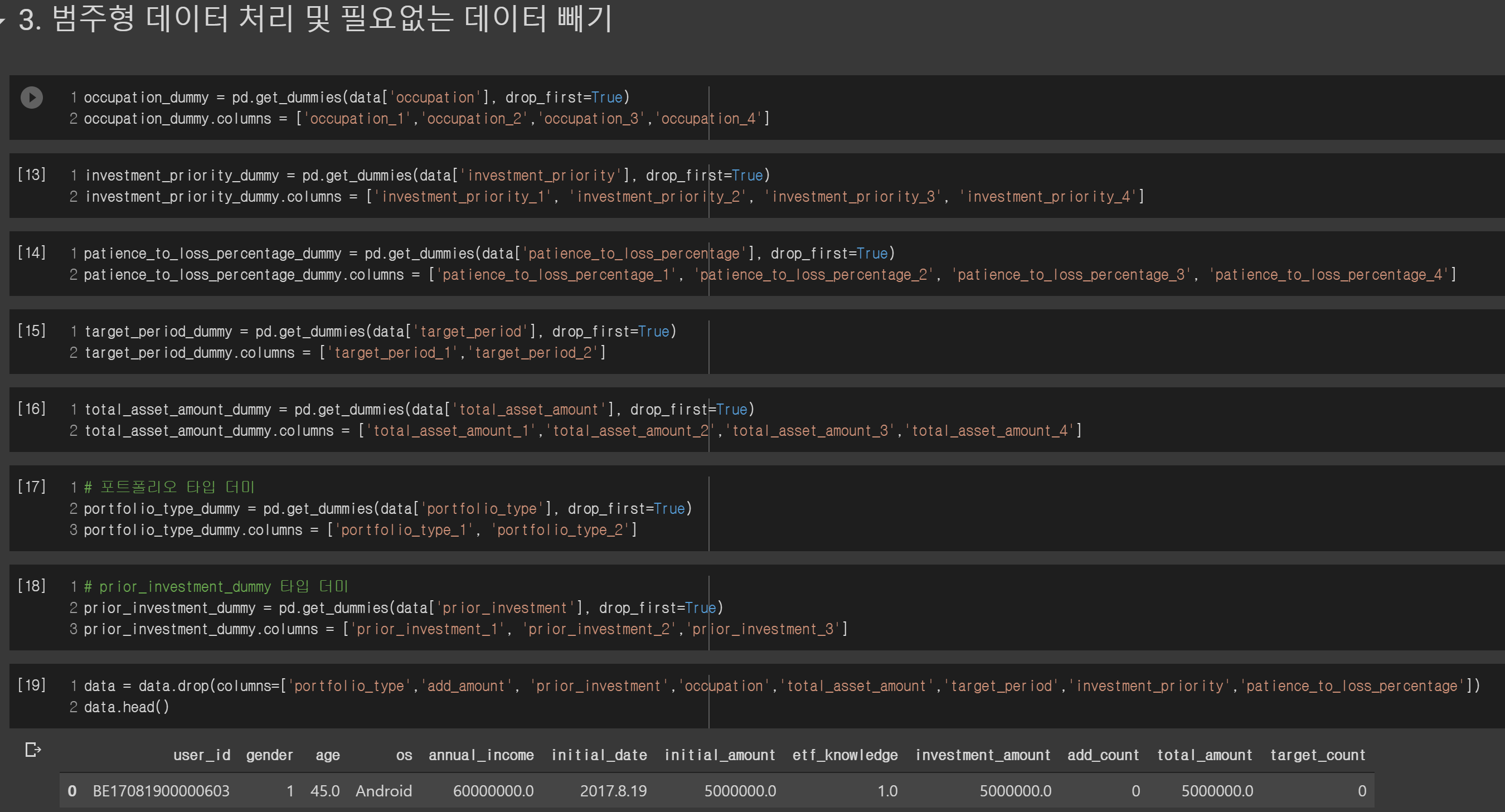
다음으로 범주형 데이터를 처리해줍니다. N-1개의 더미 변수를 만들어서 구분해줍니다.
그다음에는 data = data.drop(columns=['user_id','os','initial_date'])를 통해서 사용자 아이디, 모바일 os, 시작일을 제외시켰는데요, 이 데이터들은 사용자의 총 투자금액이나 횟수에 전혀 연관이 없다고 판단해서 제외했습니다. 만약 여러분이 생각하기에 이 데이터 역시 모델 성능에 영향을 줄 거라고 생각되면 넣으세요!
학습 및 테스트
전처리가 끝나고 이제 모델을 학습하기 전에 학습 데이터와 테스트 데이터를 분류합니다.
저희는 다음 두 가지를 할 수 있는 모델을 각각 만들어야 합니다.
1. 사용자가 과연 추가 투자를 할 것인지?
2. 사용자가 총 투자금액을 얼마나 넣을지?
두 방법에 input값 (X)는 똑같지만 예측하고자 하는 값 (y)는 total_amount와 target_count로 나뉩니다. 따라서 X값은 하나만 만들고 y값을 두 개를 만들어야 하죠.
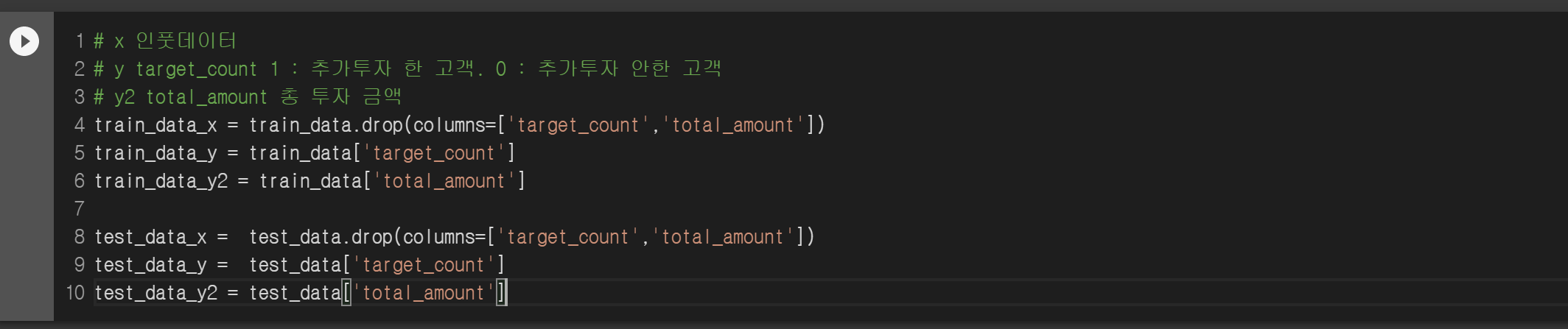
학습 데이터와 테스트 데이터를 X와 y, y2로 만듭니다. y는 추가 투자 여부를 분류하고, y2는 총 투자금액을 예측할 때 사용됩니다.

RandomForestClassifier를 이용해 분류 먼저 해보았습니다. 모델을 fit으로 학습하고 test데이터를 이용해 정확도를 측정해 보았는데 65%의 정확도가 나왔네요.
즉 사용자의 기본 정보를 가지고 이 사람이 추가 투자를 할지 안 할지 65% 확률로 맞출 수 있는 모델을 만들었습니다. 흠... 65%면 사실 반반 확률인 50%보다 매우 높은 편은 아니기 때문에 애매하네요. 하지만 사람이 판단하는 것보다는 좋은 모델이라고 할 수 있을지도 모르겠습니다.

그다음 RandomForestRegressor를 통해 사용자의 정보를 가지고 총 투자금액을 예측하는 모델을 만들었습니다. 아까와 같이 모델을 fit으로 학습하고 테스트 데이터를 이용해 r2_score를 구해보니.. 0.31이 나왔네요. 1로 갈수록 이 모델의 설득력이 높아지는 건데 31%라... 흠..
아무래도 사용자의 기본정보만 가지고 총 투자금액을 예측하는 것은 어렵나 봅니다. 아래 MSE도 구해봤는데 상당히 높은 숫자가 나왔네요. 아무래도 금액단위가 크다 보니 높게 나온 것 같습니다.
맨 아래 feature_importances는 예측하는데 가장 영향을 많이 주는 값이 무엇인지 출력해보는 함수인데, 3번째 값이 0.40이 나왔습니다. 이게 의미하는 뜻은 X값 중 3번째 값이 총 투자금액을 예측하는데 40%의 영향력이 있다는 내용입니다.
3번째 칼럼이 뭐길래 그런가 해서 봤더니 처음 투자금액(initial_amount)이네요.
당연히 처음 투자금액이 높으면 그 사람의 총 투자금액이 높겠죠? 사람이 생각하면 당연한 건데 이 모델도 같은 생각을 했다니 칭찬해줍시다 ㅋㅋ
정리하기
랜덤포레스트를 이용해 분류 및 예측을 해보았는데요, 생각보다 코드량이 많지 않았습니다.
실제로도 업무에서 사용할 때 코드의 량보다는 어떤 데이터를 포함하고 어떤 데이터를 제외할지, 어떤 값을 예측할지, 얼마만큼의 데이터를 사용할지, 모델은 어떤 것을 할지에 더 시간이 많이 소모됩니다.
결과가 나오기 전까지는 어떤 데이터 환경에서 가장 좋은 값을 뽑아내는지 모르기 때문에 하나하나 실행해보면서 답을 찾는 수밖에 없습니다.
그래서 노가다의 결정판 = 데이터 분석가 (단지 저의 생각입니다 ㅋㅋ)
아무튼 사용자 정보 가지고 이 사람이 추가 투자를 할지, 총 투자금액이 얼마일지 예측해보았는데... 생각보다 결과가 좋지 않습니다.
실제로 회사에서 써먹으려고 했는데 결과가 이렇게 안 좋으니 그냥 안 써야죠..
결과가 안 좋은 이유는 사용자에 일반 정보를 가지고는 그 사람이 투자를 할지 안 할지, 투자금액을 얼마로 할지 예측하기 어렵다는 말입니다. 아마 그 사용자에 대한 정보가 더 많다면 더 정확한 예측을 할 수 있겠죠?
이렇게 AI를 한다고 해서 항상 성공하는 것은 아닙니다. 아무리 데이터를 지지고 볶아도 원하는 결과를 못 얻을 때가 더 많죠. 이럴 땐 모델을 바꾸거나 성능을 향상하기 위해 튜닝하는 것보다 '우리의 목표가 잘못된 것은 아닌지?', '데이터가 모자라거나 부적절한 것은 아닌지?'라는 고민도 항상 동행해야 합니다.
이번 포스팅은 여기서 마치겠습니다.
감사합니다 :)
'Study > AI' 카테고리의 다른 글
| [개발자의 시선으로 보는 머신러닝 2편] 의사결정나무, 랜덤포레스트를 이용한 분류 (1) | 2020.06.21 |
|---|---|
| FAQ 챗봇 만들기 [4] - 실제 서비스 구현해보기 (3) | 2020.02.15 |
| 프로그래머즈 Dev-Matching - 머신러닝(자연어처리) 개발자 챌린지 해보기 (0) | 2020.02.01 |
| FAQ 챗봇 만들기 [3] - 많은 데이터로 실험해보기 (0) | 2019.11.22 |
| FAQ 챗봇 만들기 [2] - 모델다듬기 (0) | 2019.10.24 |