FAQ 챗봇 만들기 [2] - 모델다듬기
- Study/AI
- 2019. 10. 24. 17:29
들어가기 전에
지난 시간에는 5개의 문장으로 모델을 만들어서 유사 문장을 검색해 보았습니다. 생각보다 정확도가 그렇게 높지는 않았습니다. 이번 포스팅에서는 학습 데이터의 량도 늘려보고 모델 파라미터 값도 바꿔보면서 정확도를 더 높여보도록 하겠습니다.
github - https://github.com/tkdlek11112/faq_chatbot_learning
youtube -
목차
2019/10/22 - [Study/AI] - FAQ 챗봇 만들기 [1] - 모델만들기
2019/10/24 - [Study/AI] - FAQ 챗봇 만들기 [2] - 모델다듬기
FAQ 데이터 늘리기
일단 학습 데이터를 늘리기 위해서 어디 좋은 데이터 없나 찾아봤습니다. 영어 말고 한글로 찾으려니 더 없더라구요. 그래서 공공데이터넷에 들어가서 FAQ로 검색했더니 한국전력공사 FAQ 데이터셋이 있었습니다. 총질문의 수는 그렇게 많지 않지만, 질문과 답변으로 구성된 데이터 셋이 이번 주제에 딱 맞는 것 같아서 다운로드하였습니다. ㅎㅎ
한국전력공사 전국 지사 및 자주 묻는 질문 답변(FAQ) 링크 - https://www.data.go.kr/dataset/3068685/fileData.do
다운로드하면 xml파일과 csv파일 두 개가 있는데 그중에서 csv파일을 사용해 보겠습니다. 이번에도 마찬가지로 colab을 이용해 진행할 예정인데, 아무래도 가상 환경이라 파일을 어떻게 넣야 하는지 궁금하신 분이 있을 겁니다. colab에서는 구글 드라이브를 연동해 로컬 드라이버처럼 사용할 수 있습니다.

google.colab의 drive를 import 하고 mount를 하게 되면 링크를 하나 줍니다. 링크를 타고 구글 로그인 후 인증키를 입력하면 colab에서 구글 드라이브를 읽을 수 있습니다. 구글 드라이브에 적당한 폴더를 만들고 csv파일을 올려줍니다. 기본적으로 한글 이름으로 되어있는데 불안하니 영어로 바꿔줍시다. ㅎㅎ

pandas를 사용해 csv파일을 바로 읽어줍니다. pandas를 사용하기 위해 import pandas as pd를 해줍니다. 혹시나 utf-8인코딩 문제로 에러가 난다면 뒤에 encoding='CP949'를 넣어줍니다. 한글 문서일 때는 이걸 해줘야 하더군요. 아무튼 이렇게 csv를 바로 읽어서 사용할 수 있습니다. 원하는 필드만 보고 싶다면 faqs[['필드1','필드2']] 이런 식으로 하면 됩니다.
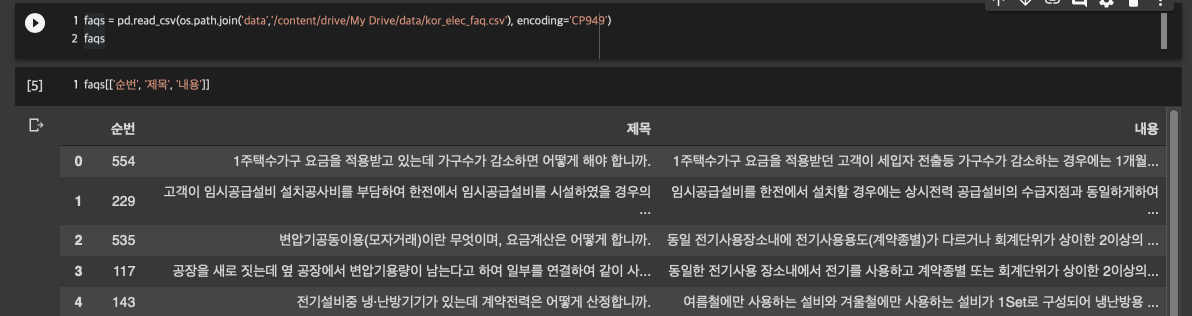
저희한테 필요한 건 index와 질문(여기서는 제목), 답변(여기서는 내용)입니다. 총 351개의 질문과 답변 데이터가 생겼으니 이전에 했던 것과 똑같은 절차로 모델을 학습시켜봅시다. 대신 이전에는 pandas 데이터가 아니었기 때문에 약~~~간의 수정이 필요하긴 합니다.

문장이 그래도 쪼꼼 많아졌다고 형태소 분석하는데 오래 걸리네요! 5개는 1초면 됬는데... 한 10초 걸린 거 같음! 이번엔 탑 5로 비슷한 걸 찾아보고 원본 문장까지 출력하도록 만들어 보겠습니다.
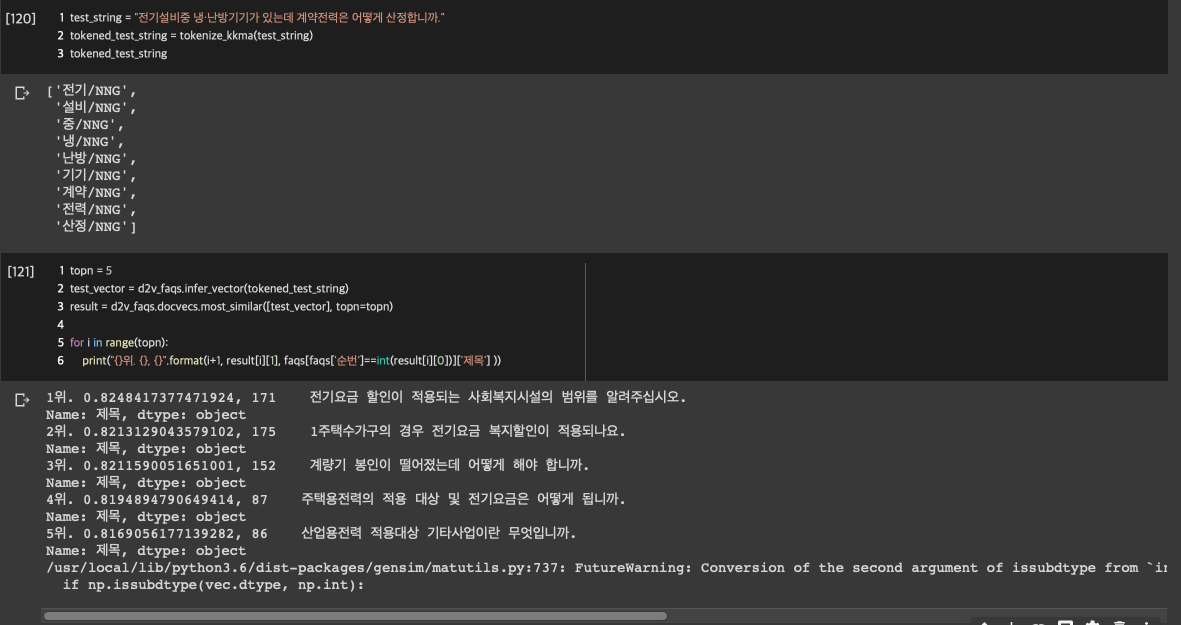
흠.. 여러분도 해보면 생각보다 성능이 좋지 습니다.ㅋㅋㅋㅋㅋ 사실 유사문서를 검색하는 doc2vec 모델의 경우 최소 만단위의 문장셋이 있어야 제대로 나온다고 합니다. 이걸로는.. 딱히 성능을 뽑아내기 힘드네요. 하지만~! 일단 여기서 성능을 올리기 위한 방법을 찾아봅시다!
튜닝 시도해보기
지금까지는 형태소분석기를 돌리고 doc2vec 모델에 넣어 바로바로 돌렸습니다. 이랬더니 결과가 상당히 참혹하더라구요...? 그래서 이것저것 고쳐보려고 합니다. 그전에~~ 여태까지 잘 돌아가던 소스가 갑자기 결과값을 잘 못 뱉는 상황이 생기더라고요. 보니까 faqs[faqs['순번']==태그값]['제목'] 이 부분이 정상적으로 동작하지 않더라구요. 그래서 곰곰이 생각하다가 그냥 인덱스를 새로 먹이자! 결정했습니다.
이전까지는 데이터 내에 적혀있는 '순번'을 인덱스로 사용했는데, 데이터는 총 351개인데 순번은 1700까지 있더라구요. 중간에 빠진 것도 몇 개 있는 건지 중복을 제거한 건지는 모르겠는데, 일단 인덱스이니 0~350으로 빈자리 없이 만들어보겠습니다.
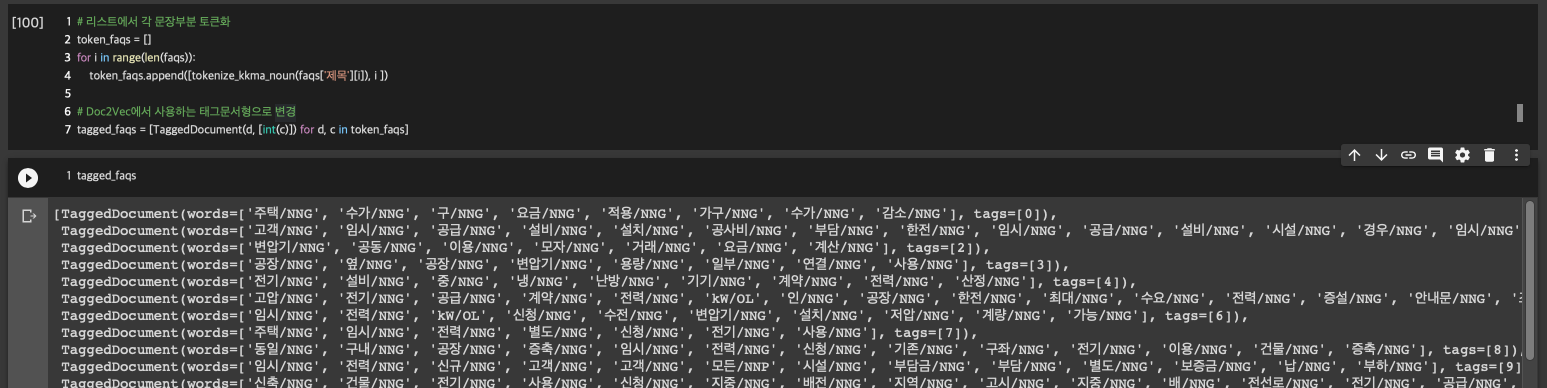
문서 원본을 수정할 필요는 없고 TaggedDocument 만들 때만 잘 넣어주면 됩니다. 기존에는 faqs['순번'][i]를 태그 값으로 넣어주었는데 그냥 i를 넣습니다. 이렇게 하면 좋은 점이 원본의 index와 태그 값이 같아지기 때문에 나중에 원문 질문을 복원할 때 faqs['제목'][tag]로 출력이 가능합니다.
그리고 이제 가장 먼저 할 거는 전처리를 조금 수정하는 건데요, 형태소 분석을 할 때 필요 없는 데이터를 제외시키는 방법입니다. 보통 문장에서는 명사와 동사가 중요하기 때문에 명사 동사 빼고는 다 날려보도록 하겠습니다.
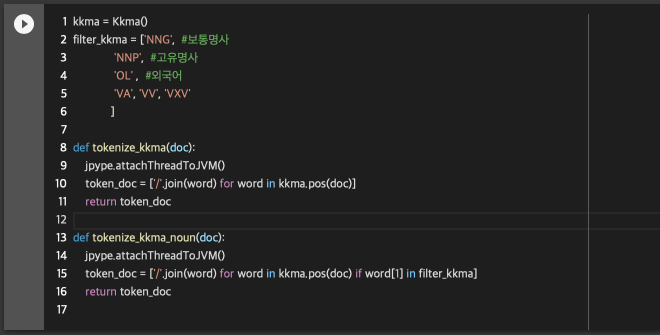
요런 식으로 filter_kkma 리스트를 하나 만들어서 형태소 분석했을 때 나오는 형태소가 filter_kkma에 포함되어 있을 경우만 학습 대상에 추가합니다. tokenize_kkma를 쓰면 전체 형태소 분석, tokenize_kkma_noun을 쓰면 동사 명사만 추출!

이제 추출된 단어가 확실히 줄었습니다. 저는 동사와 명사를 살리고 나머지를 날렸지만, 어쩔 땐 명사만 가지고 하는 경우도 있더라고요. 여기서도 여러 가지로 한번 시도를 해보겠습니다. 일단 이렇게 해서 결과가 좋게 나오는지 한번 볼까요?

해봐도 별로네요... 그럼 흠.. 모델을 한번 건드려 보겠습니다. 일단 단어가 너무 조금인데 벡터가 너무 큰가? 해서 vector_size를 20으로 줄여보겠습니다.
# make model
import multiprocessing
cores = multiprocessing.cpu_count()
d2v_faqs = doc2vec.Doc2Vec(
vector_size=20,
...
)요롷게요. 다시 한번 돌려볼게요

그다음은.. for문을 10번 돌았는데 이걸 한번 늘려볼까요?
# train document vectors
for epoch in range(200):
d2v_faqs.train(tagged_faqs,
total_examples = d2v_faqs.corpus_count,
epochs = d2v_faqs.epochs원래 10번인데 200번으로 늘려봤습니다. 20배 커졌으니 아마 속도도 20배 느려졌을 거예요. 인내심 있게 기다려줍니다 ㅎㅎ
하지만... 결과는 비슷하네요. 전혀 똑같은 게 안나오네여 ㅠㅠ 이제 이것저것 숫자를 바꿔서 모델을 만들고 테스트를 하고를 반복합니다. 네 그렇습니다. AI개발자가 해야 하는 것이 바로 이 모델 수치 바꿔가며 좋은 결과 찾는 것이죠.. 일명 노가다!! 데이터가 지금은 그렇게 크지 않아 금방금방 하지만, 나중에는 하루 종일 걸리는 모델로 진행할 때 고생 좀 할 것 같네요.
제가 다음에 수정한 건 for문이 아니라 train안에 파라미터 중에 하나인 epochs값입니다. 아마 디폴트로 되어있었을 텐데, 값을 100으로 지정해보겠습니다. 200으로 수정한 for문안에서 또 100번이 돌기 때문에 이제 엄~~~~~~청 느려졌을 겁니다. 돌려놓고 밥 먹고 와도 될 정도예요 ㅎㄷ 200*100번 하니까 2만 번이네요. colab에서 약 20분 정도 걸리네요. colab은 듀얼코어인데 자기 컴퓨터가 더 좋으신 분은 로컬에서 돌리시는 게 더 빠릅니다! 그리도 대망의 예측 결과는....!?

ㅋㅋㅋㅋㅋ.. 전혀 안 나오는군요?! 그럼 마지막으로 동사도 빼고 명사만으로 해보겠습니다.
kkma = Kkma()
filter_kkma = ['NNG', #보통명사
'NNP', #고유명사
'OL' , #외국어
]
def tokenize_kkma(doc):
jpype.attachThreadToJVM()
token_doc = ['/'.join(word) for word in kkma.pos(doc)]
return token_doc
def tokenize_kkma_noun(doc):
jpype.attachThreadToJVM()
token_doc = ['/'.join(word) for word in kkma.pos(doc) if word[1] in filter_kkma]
return token_doc이렇게 하고 kkma_noun으로 형태소 분석해서 넣어보겠습니다. 학습 200번은 에바였던 거 같아서... for문 50번 epochs=100으로 5000번 해보겠습니다.

와 드디어 순위권에 들었습니다. 비록 3위이지만 1위와 2위도 비슷한 질문으로 보이네요. 아마 명사로만 했더니 비슷한 명사가 사용된 문장을 뽑은 것 같습니다. 오히려 동사를 했을 때 보다 훨씬 좋네요. 그럼 한번 모든 문장을 넣어 보았을 때 어떤 결과가 나오는지 한번 보겠습니다.

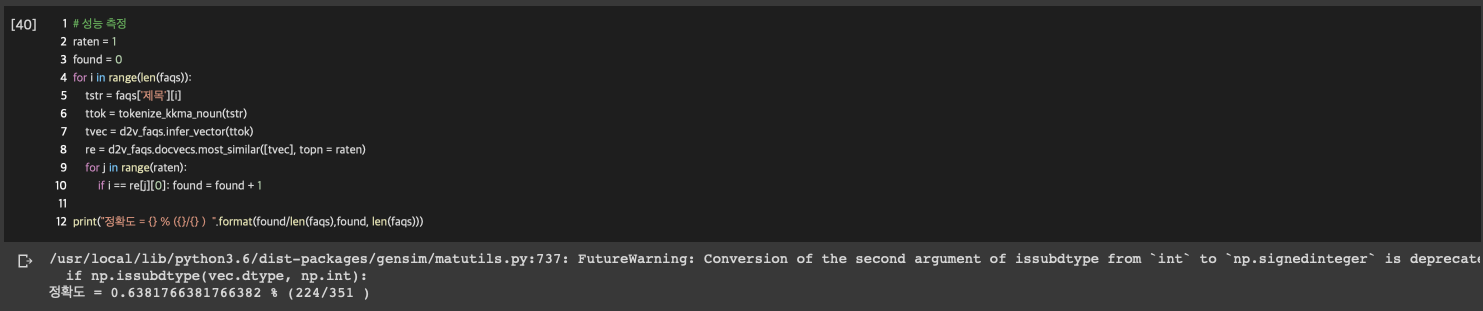
검색한 문장에 탑 5안에 속해 있는 경우를 맞다고 가정했을 때는 약 82%의 정확도를 갖네요. 탑 1로 바꾸었더니 351문장중에 224개만 정확하게 찾아냈습니다.
지금 제가 한 게 정확도라고 표현하기는 좀 그렇고 모델의 성능이라고 평가하기도 그런게 지금 제가 한 것은 분류인데 기존 학습한 데이터를 가지고 분류를 하면 원래는 100%로 분류돼야 정상입니다. (모델이 학습한 데이터로 그대로 했으니..) 하지만 doc2vec의 경우는 문장과 단어들의 유사도를 가지고 문장 벡터를 만드는 것이기 때문에 결과가 안 나올 수도 있어요. 학습을 할 때 벡터들이 조금씩 수정되기 때문에 학습이 끝나고 어떤 벡터는 비슷한 위치에 있지만 어떤 벡터는 다른 문장 학습의 영향으로 더 멀리 위치할 수 있습니다. 따라서 이 모델의 성능을 어떻게 측정할지 상당히 애매하네요. 그럼 이 모델이 예측을 제대로 하는지 기존에 있는 질문이 아닌 비슷한 질문을 만들어서 넣어보겠습니다.

"건물을 새로 지을 때 임시전력은 어떻게 신청하나요" 라는 질문을 넣어보았습니다. 사실 타깃으로 한 질문은 7번 태그를 갖는 질문이었는데 5위로 나오고, 이와 비슷한 질문이 1~4위에 분포되어있네요. 1위는 신청이라는 단어만 같은데 가장 유사하다고 판단되었습니다. 그 외에 2~4위는 뭔가 입력된 질문과 비슷하네요. 만약에 어떤 질문을 입력하면 비슷한 질문을 찾는 서비스 같은 경우에는 이 모델이 나름 의미가 있을 수 있을 것 같습니다. (짜마추기...ㅋㅋㅋㅋㅋ)
파라미터를 조금씩 수정하거나 전처리를 조금씩 바꿔가며 학습 성능을 비교해 보았는데, 이러면서 조금 불편한 점을 느끼시지 못했나요? 조금 수정할때마다 모델을 재 학습 시켜야 하니 시간이 너무 오래걸렸습니다! 대부분의 모델의 경우 세이브기능을 제공하기 때문에 파일로 저장하고 나중에 모델을 불러와서 사용할 수 있는 기능이 있기 때문에, 각 파라메터별로 모델을 만들면 이런 불편한점을 조금 해결할 수 있습니다.
모델 저장, 불러오기 해서 동시에 비교해보기
모델을 저장하는 건 간단합니다. save() 함수를 이용해 경로만 입력하면 모델 파일이 생성됩니다. colab환경에서는 구글 드라이브를 마운트 해서 사용하고 있으니, 구글 드라이브 경로에 모델을 생성해야 합니다.
d2v_faqs.save(os.path.join('data','/content/drive/My Drive/data/d2v_faqs_size100_min1_batch50_epoch100_nounonly_dm0.model'))모델을 만들 때는 나중에 사용할 때 어떤 모델인지 알기 쉽게 기록해놔야 편리합니다. 벡터 사이즈라던지 각종 파라미터 값을 어떻게 입력했는지로 모델 이름을 정하면 나중에 정말 쉽습니다. 다음으로 벡터 사이즈를 좀 줄여보고 배치도 좀 줄여서 다른 모델을 만들고 저장해보겠습니다.
d2v_faqs = doc2vec.Doc2Vec(
vector_size=50,
alpha=0.025,
min_alpha=0.025,
hs=1,
negative=0,
dm=1,
dbow_words = 1,
min_count = 1,
workers = cores,
seed=0,
epochs=50
)train 시킨 다음 위에서 저장한 모델과 다른 이름으로 (파라미터가 바뀌었으니 이름도 당연히 바뀌겠죠?)로 저장해보도록 하겠습니다.
d2v_faqs.save(os.path.join('data','/content/drive/My Drive/data/d2v_faqs_size50_min1_batch50_epoch50_nounonly_dm0.model'))이제 두 개의 모델파일이 생성되었습니다. 그럼 두개의 모델을 비교해보도록 할까요?
일단 load를 이용해 기존 모델을 읽어야 합니다.
# 모델 load
d2v_faqs_1 = doc2vec.Doc2Vec.load(os.path.join('data','/content/drive/My Drive/data/d2v_faqs_size100_min1_batch50_epoch100_nounonly_dm0.model'))
d2v_faqs_2 = doc2vec.Doc2Vec.load(os.path.join('data','/content/drive/My Drive/data/d2v_faqs_size50_min1_batch50_epoch50_nounonly_dm0.model'))
save와 반대로 load만 입력해주면 끝입니다. 이제 이 모델로 기존처럼 바로 infer_vecterd와 most_similar를 사용할 수 있습니다. 두 개의 모델을 동시에 출력해서 비교해보도록 만들어보겠습니다.


모델 1은 벡터 사이즈가 100, epoch가 100이고, 모델 2는 각각 50, 50입니다. 아무래도 벡터사이즈가 크고 많이 학습한 모델이 성능 측정이 더 높게 나왔습니다. 이런 식으로 파라미터를 수정하면 여러 개의 모델을 만들어서 비교해보면, 어느 모델이 성능이 더 좋은지 찾을 수 있습니다~!!
doc2vec 이거 정말 잘되는 거 맞는 건가..? 영어로 해볼까..
아무리 데이터가 적다고 해도 그렇지 성능이 너무 안 좋은 것 같은데... 정말 데이터가 많으면 잘되는지 영어 FAQ데이터로 테스트를 해보겠습니다.
https://www.kaggle.com/jiriroz/qa-jokes
Question-Answer Jokes
Jokes of the question-answer form from Reddit's r/jokes
www.kaggle.com
때마침 kaggle에 좋은 데이터가 있네요. 농담 Q&A인데 약간 넌센스 수수께끼 같은 질의응답이네요. 데이터가 무려 38,269개!!! 이 정도면 충분히 잘 나오겠죠? 하지만 데이터가 영어니까 쪼끔 전처리가 다릅니다. 한국어와 다르게 단어가 띄어쓰기로 정말 잘 구분되어있거든요. 전처리 안 하고 띄어쓰기로만 해도 어느 정도 결과가 잘 나오곤 합니다. ㅎㅎ 아무튼 이미 한글에 특화된 소스는 내버려두고 다음 포스팅에서 영어 약 4 만문장!! 을 해보도록 하겠습니다. 과연 한국어 쪼끔인 문장에 비해 어떻게 나올지 기대되네요~!
다음 포스팅에서 봐요~!!
'Study > AI' 카테고리의 다른 글
| 프로그래머즈 Dev-Matching - 머신러닝(자연어처리) 개발자 챌린지 해보기 (0) | 2020.02.01 |
|---|---|
| FAQ 챗봇 만들기 [3] - 많은 데이터로 실험해보기 (0) | 2019.11.22 |
| FAQ 챗봇 만들기 [1] - 모델만들기 (2) | 2019.10.22 |
| 문자열 데이터 CNN vs RNN 어떤 모델이 더 좋을까? (0) | 2019.08.07 |
| [머신러닝 무작정 따라하기] 1.머신러닝 시작하기 ~ 이진 분류기 만들기 (0) | 2018.09.10 |