문자열 데이터 CNN vs RNN 어떤 모델이 더 좋을까?
- Study/AI
- 2019. 8. 7. 12:20
CNN vs RNN, Which model is better at TEXT?
AI와 관련하여 여러 가지 공부를 하고 있는 중, 텍스트 데이터 분류에 대해 모델을 만들어야 하는 일이 생겼습니다. 여태 제가 배운 내용을 되돌아서 생각하면 당연히 RNN 모델을 사용해서 학습하는 게 좋을 것 같다고 생각했는데, 생각보다 CNN도 효율이 좋다는 연구결과가 많습니다. 이번 기회에 텍스트 데이터에 대한 RNN과 CNN에 대해 정리하려고 합니다.

CNN?
일단 각 모델에 대한 기본적인 개념을 알아야 합니다. CNN(Convolution Nerural Network)는 영상처리에서 많이 사용되는 개념으로 공간(Space) 위주의 특장점을 추출하는데 효과적입니다.라고 아마 대부분 설명할 텐데, 좀 더 쉽게 설명해보도록 하겠습니다.
이미지를 떠올려보세요. 3D로 떠올리시지 않았다면 아마 가로와 세로가 있는 2D 이미지를 생각했을 겁니다. (더 고차원으로 생각하셨다면... 존경합니다.) 상상한 이미지는 특정 색정보를 담은 픽셀로 가로와 세로만큼 꽉 차 있는 데이터입니다.

만약 위 사과그림에서 사과 꼭지라는 특징을 어떻게 설명할 수 있을까요? 맨 위에 있다? 가늘다?
사과 꼭지 부분의 데이터를 표현하면 아마 아래와 같을 것입니다.
[ 0, 0, 1, 1, 0]
[ 0, 0, 1, 1, 0]
[ 0, 1, 1, 1, 0]
[ 0, 1, 1, 0, 0]
[ 0, 1. 1, 0, 0]. ( 1은 검은색 0은 흰색이라고 가정)
위 데이터를 보면 세로축으로 0과 1이 연속적으로 발생하고, 사과 꼭지의 경계는 0 - 1, 1 - 0로 이루어져 있다는 것을 알 수 있습니다. 이게 바로 공간적인 특장점을 추출하는 방법입니다. 그림에서 우리는 사과 꼭지 부분이 검은색이고 배경은 흰색이라는 점을 직관적으로 확인할 수 있지만, 컴퓨터는 알 수 없습니다. 대신 데이터를 보고 "0 - 1, 1 - 0이 반복되는 세로형 데이터가 있네?"라고 알아챌 수 있습니다.
(비록 그게 사과 꼭지라는 것은 사용자가 알려줘야 하지만요. 이게 바로 지도 학습입니다.)
이런 식으로 공간적인 특징을 추출해서 학습하는 것이 CNN입니다. 아마 신호처리나 공업수학을 배우신 분이라면 Convolution 정의에 대해서 조금은 아실 겁니다. 하나의 필터가 다른 하나의 필터를 통과할 때의 컨벌루션 합을 구하라.. 뭐 이런 식의 문제를 푸셨을 겁니다. 푸는 방법은 두 필터가 시간에 따라 움직이면서 계산할 수 있는 면적을 다 합하면 되는 건데...(적분으로...) 자세한 식은 몰라도 개념만 알고 계신다면 아주 큰 도움이 됩니다. 중요한 것은 '면적'을 구한다입니다. 면적을 계산한다는 것은 위에서 계속 얘기했던 공간적인 계산을 한다는 것이기 때문이죠.
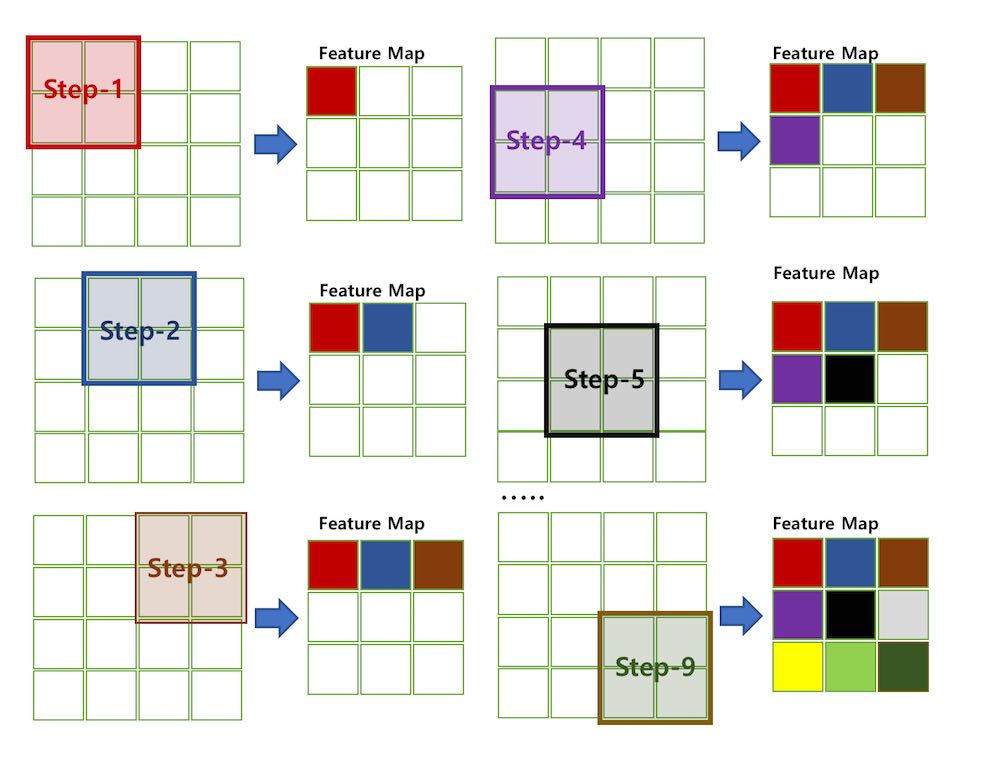
실제로 CNN 모델의 학습과정을 보면 아래와 같이 원본 이미지를 필터를 사용해 훑고 지나가면서 특장점(Feature Map)을 추출하는 것을 볼 수 있습니다.
RNN?
RNN(Recurrent Neural Network)는 공간보다는 시간(time flow)에 초점을 둔 모델입니다. 흔히 시퀀스(sequence) 데이터를 처리한다고 하는데, 시간적이든 어떤 기준이든 순서가 있는 데이터에 적합합니다. 일별 날씨로 예를 들어 볼까요?
월요일은 20도, 화요일은 21도, 수요일은 22도, 목요일은 23도일 때 금요일은? 아마 우리 모두 금요일은 24도일 거라고 쉽게 추측이 가능할 겁니다. 이렇게 시간적인 순서가 있는 데이터는 앞 뒤의 데이터의 영향을 줍니다. 우리가 목요일이 23도인 것을 확인하고 금요일이 24도일 것이라 예측한 것처럼 말이죠. 하지만 앞서 말한 것처럼 시간적인 순서뿐만 아니라 어떤 순서에서도 쓸 수 있습니다. 우리가 하는 말도 일종의 순서가 있습니다.
| 안녕하세요? 제 이름은 문규진입니다. -> 1. 안녕하세요? 2. 제 3. 이름은 4. 문규진입니다. 오늘 너무 더운데? 어디 카페에 가서 시원한 것좀 먹자. -> 1. 오늘 2. 너무 3. 더운데? 4. 어디 5. 카페에 6. 가서 7. 시원한 8. 것좀 9. 먹자. |
이렇게 순서를 정해 잘라놓고 보니 앞뒤에 단어가 연관 있어 보이지 않나요? ㅎ_ㅎ? 각 언어마다 문법이라는 것이 있기 때문에 우리가 생각하는 것보다 더 많은 연관관계가 있을 겁니다. 이런 식으로 순서상의 데이터의 특징을 고려해 학습하는 모델이 RNN입니다.
그럼 당연히 RNN으로 해야 되는 거 아닙니까?
네 이렇게 CNN과 RNN의 정의를 살펴본다면, 텍스트 분석에는 당~~~~~~연히 RNN을 써야 좋고, 당연히 써야 하며 무조건 써야 될 것 같습니다. 텍스트는 순차적인 데이터니까요! 그러나 이상하게도(혹은 당연하게도) CNN모델 역시 텍스트 분석에 많이 사용되며 좋은 결과를 내놓고 있습니다. 그럼 어떻게 공간적인 특징을 추출하는 CNN으로 텍스트 분석을 하는지 살펴보도록 하죠.
일단 우리의 고정관념을 깸과 동시에 발상의 전환이 필요합니다.
|
고정관념 1 : "CNN은 이미지 분석에 좋아 2차원적으로 해야지 네모난 필터를 씌울 수 있지" 발상의 전환 : "텍스트 데이터는 순차적인 1차원 데이터이다" |
여기서 감이 오신 분이라면 아마 엄청난 센스를 타고나신 분입니다. :)
바로 입력 텍스트 데이터의 모양을 조금 바꿔보는 건데요. 우리가 일자로 나열한 단어들을 세로로 세워보는 겁니다.
|
안녕하세요? 제 이름은 문규진입니다. |
어때요? 우리가 알고 있던 텍스트 데이터가 2차원 모양의 데이터셋으로 변경되었습니다. 이제 여기에 필터를 씌워 공간적인 특장점을 추출하게 될 텐데, 이렇게 2차원으로 바꾼 텍스트 데이터의 공간적인 특장점이 의미하는 바가 뭘까요? 네, 바로 RNN에서 다루고 있는 "순서"입니다. 바로 앞 단어가 위에 오고 뒷단 어가 아래 오기 때문에 자신 위, 아래가 바로 이전, 다음 순서를 의미하게 됩니다. 결국 CNN도 RNN과 같이 "순차적"인 특징을 추출할 수 있게 되는 것이지요. 하지만 완벽하게 RNN과 똑같지는 않습니다. 왜냐하면 필터의 크기에 제한이 있기 때문이지요. CNN에서는 보통 3 x 3 크기의 필터를 사용합니다. 이는 한 번에 볼 수 있는 데이터가 자신을 포함해 위로 하나, 아래로 하나라고 생각할 수 있지요. 즉 바로 전, 후 단어만 참고할 수 있습니다. (필터의 크기가 커지면 더 볼 수 있습니다.) 하지만 RNN은 전체적인 순서의 특징을 고려할 수 있지요 (너무 커지면 그 특징을 못 찾는 문제가 발생하기도 합니다)
아니 선생님.. 그럼 전 어떤 걸 사용해야 합니까?
데이터 분석하기도 전에 엄청난 고민에 휩싸입니다. RNN을 쓸려고 했는데 CNN도 괜찮다네... 그럼 뭘 써야 하죠?
다행히도 세상에 많은 선생님들께서 미리 둘의 차이를 분석하고 연구하고, 결과까지 내놓은 수많은 사례들이 있습니다. 저희는 그것을 참고하여 활용하기만 하면 됩니다. 일단 요점은 한 가지입니다.
짧은 문장엔 CNN, 길면 RNN.
쉽죠? CNN은 참고하는 범위가 RNN보다 적기 때문에 짧은 문장에서 특징을 잘 추출합니다. 반면 RNN은 전체적인 순서를 고려하기 때문에 보다 더 긴 문장에 적합합니다. 간단한 상품평 같은 문장에는 CNN이, 소설이나 뉴스처럼 많은 정보를 담은 긴 글은 RNN이 더 효과적입니다. 참고로 속도는 CNN이 RNN보다 빠릅니다. 바로바로 응답이 나와야 한다면 CNN, 여유가 있다면 RNN입니다.
하지만, 제일 좋은 방법은, 둘 다 해보고 좋은걸 선택하는 겁니다. ^^
'Study > AI' 카테고리의 다른 글
| 프로그래머즈 Dev-Matching - 머신러닝(자연어처리) 개발자 챌린지 해보기 (0) | 2020.02.01 |
|---|---|
| FAQ 챗봇 만들기 [3] - 많은 데이터로 실험해보기 (0) | 2019.11.22 |
| FAQ 챗봇 만들기 [2] - 모델다듬기 (0) | 2019.10.24 |
| FAQ 챗봇 만들기 [1] - 모델만들기 (2) | 2019.10.22 |
| [머신러닝 무작정 따라하기] 1.머신러닝 시작하기 ~ 이진 분류기 만들기 (0) | 2018.09.10 |