서버개발자가 되는법 - #7 To-Do 앱 만들기 [3], To-Do 리스트 조회 및 페이징처리
- Course/서버개발자가 되는법
- 2021. 3. 22. 23:15
목차 - 2020/09/29 - [Study/서버] - 서버개발자가 되는법 - 목차
git - tkdlek11112/server_dev at 서버개발자_7 (github.com)
git(화면) - tkdlek11112/todo-list (github.com)
유튜브 - 바쁘신 분들은 유튜브 스킵해도 됩니다~
들어가기 전에
지난 시간에는 To-Do 목록에 대한 C.R.U.D API를 만들어봤습니다. (아주 간단하게)
오늘은 지난 시간에 만든 API를 살짝 업그레이드할 예정인데요. 일단 로그인한 사용자의 To-Do 목록만 조회하는 기능과 페이징 처리를 집중적으로 다룰 예정입니다.
리액트 docker에 예제 3/실습 3이 추가되었습니다. github에서 새로 받아주세요~!
화면 맛보기
일단 [예제 3] 화면부터 볼까요?
기존에 [예제 1]과 [예제 2] 화면이 하나로 합쳐졌는데요. 또 특이한 점은 To-Do 목록 창 아래 화살표가 있다는 점입니다. 그리고 목록이 아무것도 안 나옵니다. 기능을 보면 아래와 같습니다.
- 실습 1 + 실습 2
- 로그인하면 로그인 한 ID로만 To-Do 조회
- 10개씩 페이징 처리
일단 [실습 1] + [실습 2]는 알겠고, '로그인하면 로그인 한 ID로만 To-Do 조회'?? 이거는 ID를 mychew라고 쳐보면 한방에 이해 갑니다. 현재 예제 3에서는 id와 비번을 아무거나 입력해도 로그인이 되는데요. ID를 mychew라고 하고 비번을 아무거나 입력해보세요.

그럼 짠~~ 하고 목록이 나오게 됩니다. 이전과 다른 점은 목록명 옆에 ID가 나옵니다 ㅋㅋ
아 그런데 생각해보니, 실제 사용자는 어차피 자기가 로그인해서 자기 꺼를 본다면 ID가 안 나와도 되겠네요. ㅋㅋㅋ 개발할 때 쉽게 구분하려고 넣었는데 나중에는 빼야겠습니다.
아무튼, 이렇게 로그인한 사용자의 To-Do만 보면 되고요. 여기서 To-Do를 여러 개 생성해봅시다. 구분되기 쉽게 5번 투두, 6번 투두~~~~~ 12번 투두까지 만들어봅시다.
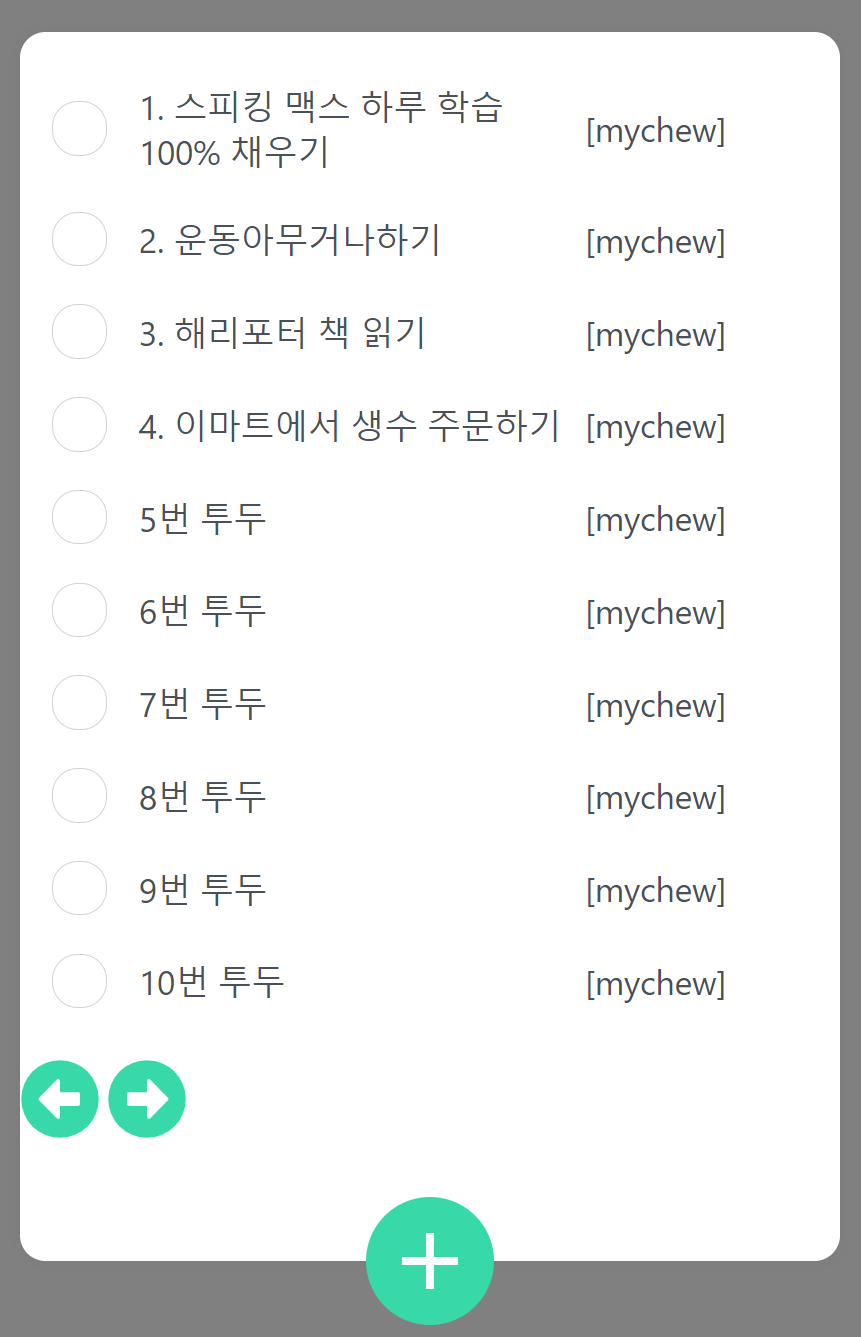
그럼 10번 이상부터는 화면에 안보입니다. 아래 화살표가 있는 거 보니 다음 페이지로 갔겠죠? 오른쪽 화살표를 눌러봅니다.

네 이렇게 페이지 처리를 한다고 해서 '페이징'이라고 합니다 ㅋㅋ
[예제 3]을 통해 우리가 본 기능은 크게 두 가지인데요.
1. 로그인한 ID로 C.R.U.D 하기
2. 페이징 처리하기
하나씩 만들어볼까요?
조회 API 개발
로그인한 ID로 To-Do를 조회한다고 하더라도, 로그인과 회원가입 API는 변한 게 없습니다. 어쨌든 클라이언트에서 로그인하고 나서 ID를 저장했다가 To-Do를 조회할 때 Input에 넣어주기만 하면 되거든요. 이건 클라이언트 몫~!
* To-Do 조회 API
URL : http://localhost:8000/todo/select
입력필드
user_id (string) : 사용자 id
page_number (int) : 페이지 번호
출력필드
tasks (Array) : [
id (int): To-Do 고유 아이디
name (string): To-Do 이름
done (boolean): To-Do 완료 여부
]
is_last_page (boolean): 마지막 페이지 여부
전체 조회 API와 다르게 [실습 3]에서의 조회 API는 입력 필드가 있습니다. user_id와 page_number를 볼 수 있는데요, user_id는 해당 사용자의 To-Do를 찾기 위한 입력 필드이고, page_number는 현제 페이지 번호입니다. 페이징을 처리하는 방법은 엄청 많은데, 이번 포스팅에서는 page_number가 0이면 현재 첫 번째 페이지를, 1이면 그다음 페이지를 보여줍니다.
서버에서는 page_number가 0이면 처음 10개의 데이터(1~10)를 내려주면 되고, page_number가 1이면 처음 10개를 건너뛰고 다음 10개의 데이터(11~20)를 내려주게 됩니다. 클라이언트에서는 현재 페이지 번호를 저장하고 있기 때문에 현재 페이지 값이 2이면 왼쪽 화살표를 누르면 1을 보내고 오른쪽 화살표를 누르면 3을 보내게 됩니다.
서버는 단순히 클라이언트에서 올라오는 page_number만 보고 위치를 선정하면 됩니다. 단 해당 페이지의 데이터가 10개가 안 되는 경우를 체크하고, 다음 페이지가 있는지 여부를 판단해서 클라이언트에게 알려줘야 합니다. 그렇지 않으면 클라이언트가 다음 페이지의 유무를 모르기 때문에 더 이상 데이터가 없어도 다음, 다음, 다음 페이지를 호출할 수 있습니다. ㅎㅎ
# ~/todo/views.py
class TaskSelect(APIView):
def post(self, request):
user_id = request.data.get('user_id', None)
page_number = request.data.get('page_number', None)
# print("user_id = ", user_id, ", page_number = ", page_number)
is_last_page = True
# user_id를 올리는 경우
if user_id and not "":
tasks = Task.objects.filter(user_id=user_id)
else:
tasks = Task.objects.all()
if page_number is not None and page_number >= 0:
# print('총 todo 수 : ', tasks.count())
if tasks.count() <= 10:
pass
elif tasks.count() <= (1 + page_number) * 10:
tasks = tasks[page_number * 10:]
else:
tasks = tasks[page_number * 10: (1 + page_number) * 10]
is_last_page = False
# page_number가 없는경우.. 이전 버전 api이거나 실수로 못올렸거나
# 그냥 0으로 생각하고 응답줄지 아니면 에러 응답할지 선택해야함.
else:
pass
task_list = []
for task in tasks:
task_list.append(dict(id=task.id,
userId=task.user_id,
name=task.name,
done=task.done))
return Response(dict(tasks=task_list, isLastPage=is_last_page))
일단 기존에 없던 input field가 두 개가 생겼습니다. user_id와 page_number를 받아서 user_id로 일단 해당 사용자의 To-Do만 가져오는 로직을 넣습니다.
여기서 중요한 건, 기존에 [실습 2]에서는 user_id를 올리지 않기 때문에 user_id를 올리지 않는 경우도 생각해줘야 한다는 점입니다. 따라서 user_id가 있으면 Task.objects.filter(user_id=user_id)를 통해 해당 유저의 데이터만 가져오고, 만약 user_id가 없으면 기존과 똑같이 Task.objects.all()로 모든 To-Do를 가져옵니다.
실제 현업에서도 사용하던 기능을 수정할 때, 이전 버전으로 콜이 올라오면 어떻게 될지 많이 고려하면서 작업을 합니다. 정말 리스크가 큰 경우에는 시스템을 멈추고 작업을 하지만, 최대한 무중단 서비스를 위해 이전 버전을 호환할 수 있게 코드를 수정합니다. 여기서도 이전 버전인 [실습 2]의 요청을 위해 input이 있을 때와 없을 때 모두 정상 처리되도록 코드를 수정합니다.
page_number의 경우에는 생각보다 복잡한 로직이 들어가는데요, 일단 해당 사용자의 전체 To-Do 리스트의 개수를 알아야 합니다. 전체 리스트의 수를 알면 전체 페이지의 수를 계산할 수 있는데, 전체 페이지 수를 알아야 클라이언트에게 다음 페이지가 있는지 없는지 여부를 알려줄 수 있습니다.
예를 들어 현재 클라이언트가 첫 번째 페이지[page_number=0]를 요청했는데 사용자의 전체 To-Do가 10개 미만이라서 페이지가 하나밖에 없다면, 서버는 클라이언트에게 "두 번째 페이지는 없다. 지금 요청한 페이지가 마지막이다"라는 정보를 내려줘야 합니다.
is_last_page = True
if page_number is not None and page_number >= 0:
# print('총 todo 수 : ', tasks.count())
if tasks.count() <= 10:
pass
elif tasks.count() <= (1 + page_number) * 10:
tasks = tasks[page_number * 10:]
else:
tasks = tasks[page_number * 10: (1 + page_number) * 10]
is_last_page = False
# page_number가 없는경우.. 이전 버전 api이거나 실수로 못올렸거나
# 그냥 0으로 생각하고 응답줄지 아니면 에러 응답할지 선택해야함.
else:
pass
위 코드가 실제로 페이징 처리의 전부입니다. 여기도 역시 page_number가 input으로 안 들어오는 이전 버전을 대비해서 예외처리를 해주었습니다. page_number가 None이면 그냥 스킵하고 pass 하게 되죠. 저는 서버에서 강제로 한 페이지당 보이는 데이터의 수를 10개로 고정했습니다. 따라서 1page = 10이죠.
처음 if문에서 총 To-Do의 수가 10개 이하일 때를 체크하게 됩니다. 이게 무엇을 의미할까요? To-Do의 수가 10개 이하라면 이 사용자는 한 페이지로 모든 To-Do를 보여줄 수 있습니다. 따라서 페이징 처리를 할 필요가 없죠. 그 아래 있는 elif문에서는 To-Do의 수가 클라이언트가 요청한 (page_number + 1) * 10 보다 작은지 체크합니다. 이 부분이 바로 다음 페이지가 있는지 없는지를 검사하는 로직입니다.
예를 들어 요청한 페이지가 첫 페이지(page_number = 0)라면 보이는 데이터는 1번~10번까지입니다. 두 번째 페이지라면 11번~20번까지죠. 즉 (page_number+1) * 10을 하게 되면 가장 마지막에 보이는 데이터의 번호를 가리킵니다. 만약 To-Do의 수가 해당 페이지의 가장 마지막 데이터 번호보다 적으면 다음 페이지는 없습니다. 하지만 가장 마지막 데이터의 번호보다 To-Do의 수가 많으면 다음 페이지가 존재하죠. 따라서 elif tasks.count() <= (1 + page_number) * 10이 참이면 마지막 페이지입니다.
위 두 개의 if문이 다 거짓이면 tasks.count()가 클라이언트가 요청한 마지막 데이터보다 많다는 것이기 때문에, is_last_page를 false로 줘서 다음 페이지가 있다는 것을 클라이언트에게 알려줍니다. 여기서는 마지막 페이지가 있는지 여부를 클라이언트에게 전달했는데, 이건 쓰는 곳마다 케바케입니다. 마지막 페이지 여부를 주는 경우도 있고, 다음 페이지 여부를 주는 곳도 있습니다.
task_list = []
for task in tasks:
task_list.append(dict(id=task.id,
userId=task.user_id,
name=task.name,
done=task.done))
return Response(dict(tasks=task_list, is_last_page=is_last_page))
최종적으로는 task_list에 To-Do를 담아서 줍니다. 여기서 추가된 것은 To-Do를 담을 때 사용자의 ID인 userId가 추가된 점, 그리고 Response로 is_last_page를 준다는 점입니다. 이걸로 To-Do 리스트와 마지막 페이지 여부를 주는 조회 API 개발 완료했습니다.
기타 API 수정
자 이제 조회를 수정했고, 생성과 삭제, 업데이트도 수정해줘야 합니다. 수정할 게 없는데 뭘 수정하지?라고 생각하실 수 도 있는데, 이번에 로그인 한 ID로만 조회가 되도록 변경했으니, 생성과 수정, 삭제에서도 필요한 작업이 있습니다.
어떻게 무엇이 바뀌었는지 곰곰이 생각해봅시다.
기존에 우리는 조회 API에서 모든 사용자의 To-Do를 내려주었습니다. 그리고 새로운 To-Do를 생성할 때 내려준 To-Do의 가장 마지막 ID + 1로 새로운 To-Do를 만들었습니다. 아무 문제없습니다.
하.지.만 이제는 조회를 하면 해당 사용자의 To-Do만 내려줍니다. 만약 ID가 1, 2, 3을 갖는 To-Do는 A사용자의 것이고, ID가 4, 5, 6인 To-Do는 B사용자라고 해봅시다. A사용자가 To-Do를 조회하면 1, 2, 3만 내려갑니다. 기존 로직대로라면 클라이언트가 새로 To-Do를 만들면 ID 4로 만들게 됩니다. 그럼 B사용자가 가지고 있는 To-Do와 ID가 겹치기 때문에 에러가 납니다. 따라서 이 부분을 해결해줘야 합니다.
일단은 이 문제는 애초에 설계를 잘못해서 발생한 문제입니다. 설계할 때부터 사용자별로 To-Do의 ID를 독립적으로 구성했다면, 즉 사용자 ID + To-Do ID로 키를 잡았다면 A사용자가 ID 1, 2, 3의 To-Do를 가지고 있어도 B사용자가 ID 1, 2, 3의 To-Do를 가질 수 있게 됩니다. 하지만 처음에 만들 때 전체 사용자 꺼를 조회하게 만들었고, 지금은 개인별로 조회가 되게 바뀌었으니 이런 문제가 생기게 된 것입니다.
아무튼 이 문제를 해결하기 위해 To-Do를 생성할 때 클라이언트에서 ID값을 올리지 말고 자동으로 서버에서 생성되게 만들겠습니다. Django에서는 ID값을 주지 않고 Object를 Create 하면 자동으로 ID값을 할당하기 때문에 그걸 이용하는 겁니다 ㅎㅎ 대신 이렇게 되면 사용자별로 ID가 연속되지 않는다는 단점이 있습니다만 겹치지는 않게 되니까 문제는 해결됩니다. 만약 사용자별로 To-Do가 연속돼야 한다면 이 방법은 못씁니다. 현재 만들고 있는 서비스의 로직을 잘 생각해서 수정 방안을 고려하는 것도 서버 개발자에게 필요한 역량입니다.
아무튼 TaskCreate를 다음과 같이 고칩니다.
class TaskCreate(APIView):
def post(self, request):
user_id = request.data.get('user_id', None)
todo_id = request.data.get('todo_id', None)
name = request.data.get('name', None)
# 이전버전 호환을 위해 todo_id가 들어오고 안들어오고로 분기
if todo_id:
task = Task.objects.create(id=todo_id, user_id=user_id, name=name)
else:
task = Task.objects.create(user_id=user_id, name=name)
return Response(data=dict(id=task.id))
if문 하나를 추가했습니다. 이전 버전인 [실습 2]에서는 todo_id를 input으로 올려서 그 id를 기반으로 To-Do를 만들지만, 새로 바뀐 TaskCreate는 Input에 todo_id가 없습니다. 따라서 input에 todo_id가 있다면 기존과 똑같이 todo_id를 사용해 만들고, 만약 입력된 todo_id가 없다면(None) create 할 때 id를 넣지 않고 만듭니다. create에 id값을 넣지 않으면 자동으로 다음 번호로 만들어 줍니다 :) 장고 짱
그리고 여기서 또 중요한 것은 응답으로 새로 만들어진 task.id를 준다는 점입니다. 이전 실습에서는 클라이언트에서 올라온 id로 To-Do를 만들었기 때문에 서버에서 id를 주지 않아도 클라이언트가 새롭게 생성된 To-Do의 id값을 알고 있지만, 이제는 자동으로 생성되기 때문에 서버가 클라이언트한테 id를 알려주어야 삭제나 업데이트를 할 때 id를 입력할 수 있습니다.
이것으로 페이징 처리와 ID 입력 끝!
페이징 처리하는 법에 대한 고찰
사실 페이징 처리 방법은 따로 주제로 잡아서 포스팅을 하려고 계획했었는데, 강의를 계속하면서 자연스럽게 페이징과 만나게 되었습니다 ㅋㅋ 그만큼 자주 쓰인다는 것이죠.
풀 스택이나 프론트를 개발하셨던 분들은 오히려 페이징에 익숙하실 겁니다. 가장 많이 만드는 앱인 "게시판"을 구현하기 위해서는 페이징이 기본적으로 들어가기 때문이죠. 보통 페이징을 처리해주는 패키지나 라이브러리를 사용해서 구현하게 되는데, 단순히 라이브러리를 가져다가 사용하는 것이 아니라 페이징이 어떻게 돌아가는지 구조를 확실히 알 필요도 있습니다. 현업에서도 제로베이스에서 페이징 처리를 구현하는 경우도 많고, 서버 개발자로서 클라이언트 개발자와 얘기할 때 자주 등장하는 기술이기 때문입니다.
이번 To-Do 프로젝트에서는 아주 간단한 페이징 방법이 쓰였습니다. 클라이언트에서는 페이지 번호만 올리고 서버에서는 마지막 페이지 여부만 줬는데요, 실제로 현업에서는 아주 다양~~~~ 한 방법의 페이징 기법들이 있습니다. 페이지 번호와 다음 페이지 여부를 주는 방법, 가장 마지막으로 조회한 id와 다음 페이지 여부를 주는 방법, 페이지 번호화 한 번에 조회할 개수를 주는 방법, 이 데이터들을 body영역에 주는 방법, header영억에 주는 방법 등등 회사마다 가지각색인데요, 따로 공통적으로 정의된 포맷이 없기 때문입니다.
하지만 공통으로 적용하기 어려운 게 이 페이징인데요, 왜냐하면 이번 포스팅에서 쓰인 페이징은 실시간으로 변하는 데이터에는 적합하지 않습니다. 우리가 페이지 번호 1을 조회하고 2를 조회하면 11~20번째 데이터를 내려주게 되는데 만약 1번 페이지를 조회하고 2번 페이지를 조회할 때 새로운 데이터가 생기면 어떻게 될까요? 만약 최신 순으로 정렬이 되어있다면 새로 생긴 데이터는 1번이 될 것이고 기존에 1번 데이터는 2번이 되고, 2번 데이터는 3번이 되면서 번호가 하나씩 밀리게 됩니다. 결국 2번 페이지를 조회했을 때 우리는 11~20번째 데이터를 원했는데 데이터가 하나 생기면서 기존에 10~19번째 데이터를 조회하게 됩니다. 이해되셨나요?
만약 게시판처럼 하단에 페이지 번호들이 나열돼있고 번호를 누를 때마다 화면에 보이는 게시물들이 다 바뀌는 경우라면 사용자가 인지 못할 수 도 있습니다. 하지만 요즘 모바일 UI에서 '더보기'를 하게 되면 기존 리스트 아래 데이터가 붙여서 나오는 경우에는, 똑같은 데이터가 두 개가 보일 수 있습니다. (첫 번째 10개 조회한 거에 10번과 두 번째 10개 조회한 거에 1번이 같은 데이터가 됩니다!!)
그밖에도 데이터 성격, 서비스 성격에 따라 알맞은 페이징 처리, 효과적인 페이징 처리가 존재하기 때문에 잘 따지고 구현해야 합니다. 추가적으로 이 가이드를 클라이언트가 할지 서버가 할지 참 난 애한 문제라.. 서로 잘 알고 있어야 협업이 잘됩니다 ㅎㅁㅎ 우리 클라이언트 개발자한테는 밀리지 말자고요~
정리하면서
이번 시간에는 페이징에 대해 살짝 깊게 다뤄봤습니다. CRUD와 페이징만 알면 어느 정도 API들은 다 만들 수 있지 않을까~? 생각됩니다.
다음 시간에는 클라이언트가 올리는 user_id를 공통영역으로 빼서 받도록 처리할 건데요, 지금은 body영역에 user_id필드에 올리게 되어있지만, 실제로 모든 서비스에는 user_id가 필요할 겁니다. 그럼 계속 body영역에 추가하는 것보다 공통된 헤더 영역으로 빼는 게 좋겠지요?
다음 시간에는 회사에서 말하는 '공통'영역에 대해 좀 만들어보도록 하겠습니다.
제 생각에는 이 '공통'영역이라는 놈이 만든 소스를 이해하기 어렵게 만드는 범인이라고 생각합니다. 하지만 범인을 잘 찾을 수 있는 기술을 갖게 된다면 남이 만든 소스 분석도 쉬워집니다 :)
그럼 다음 강의에서 뵙겠습니다.
'Course > 서버개발자가 되는법' 카테고리의 다른 글
| 서버개발자가 되는법 - #9 로그의 중요성, Django에서 Log 남기기 (2) | 2021.05.16 |
|---|---|
| 서버개발자가 되는법 - #8 To-Do 앱 만들기 [4], 공통 처리 영역 만들기 (3) | 2021.04.23 |
| 서버개발자가 되는법 - #6 To-Do 앱 만들기 [2], 기획과 화면을 보고 만들어보기 (2) | 2021.02.21 |
| 서버개발자가 되는법 - #5 To-Do 앱 만들기 [1], 기획과 화면을 보고 만들어보기 (0) | 2021.02.12 |
| 서버개발자가 되는법 - 목차 (0) | 2020.09.29 |