[개발자의 시선으로 보는 머신러닝 2편] 의사결정나무, 랜덤포레스트를 이용한 분류
- Study/AI
- 2020. 6. 21. 00:54
유튜브 - 자세한 설명은 유튜브에~ 빠르게 보고싶은 분은 영상 생략 가능~!
들어가기 전에
1편보다 2편을 먼저 쓰는 신기한 포스팅입니다. ㅋㅋㅋ 1편은 나중에 쓸라고... 참고로 1편 내용은 선형 회귀와 로지스틱 회귀.
AI를 사용하는 사람들이 하는 고민중에 하나는 AI 모델들이 너무 블랙박스라는 점입니다. 내부의 모델이 어떻게 되어있는지 명시적으로 알지 못하고, 학습을 진행한 모델이 알아서 예측해주는 값을 이용하기 때문에 도대체 왜 이런 값들을 이렇게 예측했지?라는 의문점이 들 때가 많아요.
예를 들어 선형회귀 모델은 y = ax + b라는 공식을 만들고 사용자가 수많은 (x, y) 데이터를 집어넣어서 최적화된 a, b값을 찾습니다. 모델이 a = 3, b = 4라고 학습했다면 x = 4라는 값을 집어넣으면 y = 3 * (4) + 4이므로 모델이 x = 4에 대해서 y = 16이라고 예측하게 되죠.
우리는 모델이 a = 3, b = 4라고 정의했기 때문에 x = 4일때 y = 16이 나오는 것을 알 수 있습니다. 하지만 모델은 왜 a = 3 b = 4라고 정의했을까요?
모델 안에서 수많은 수학공식과 최적화 알고리즘들이 학습 데이터에 대해서 여러번 계산해서 모든 학습 데이터에 대해 가장 근접하게 만족하는 a와 b값을 찾았을 거라고 우리는 추측할 수 있습니다. 하지만 그 수학 공식이나 알고리즘 등을 명시적으로 표기할 방법이 없어요. 그래서 등장한 게 DT입니다. DT는 트리구조를 사용해 모델이 어떤식으로 데이터를 분류하는지 명시적으로 나타낼 수 있습니다. 예를 들면 아래처럼요!
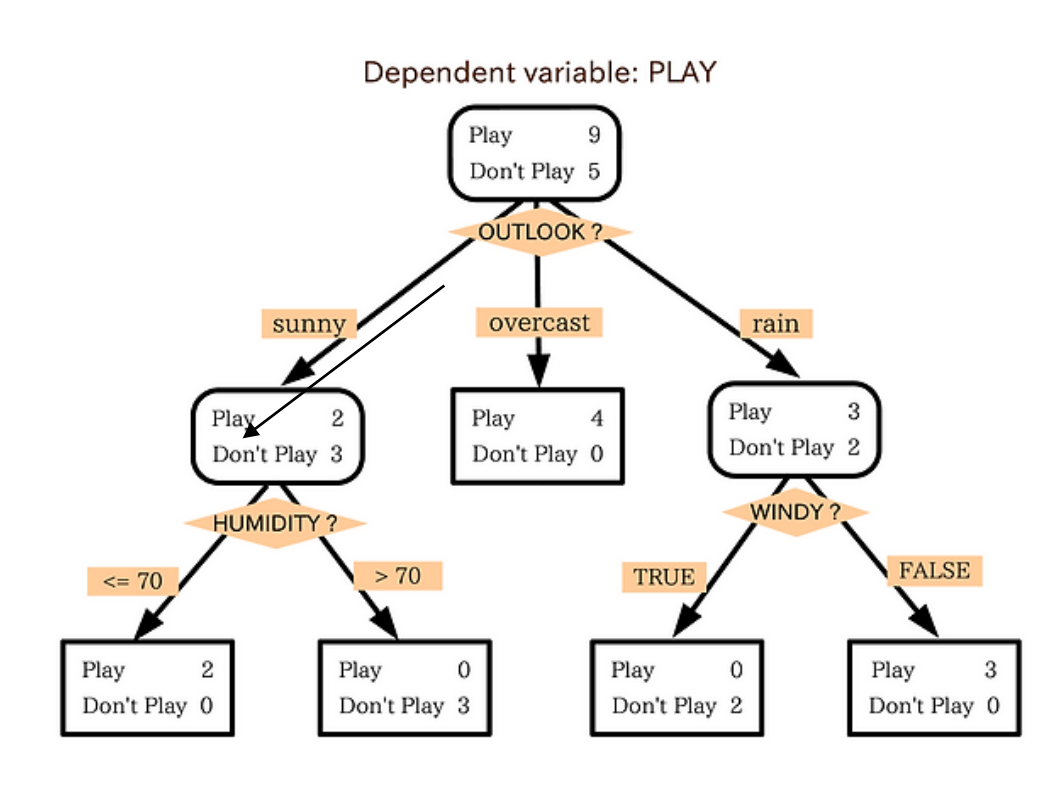
Play가 높으면 나가 놀고 Don't Play가 높으면 나가서 놀지 않는 것을 표시한 DT 모델입니다. Depth 1에서는 밖에 날씨가 맑은지, 흐린 지, 비가 오는지를 구분하고 있습니다. 밖에 날씨가 맑은데 습도가 70% 이하면 나가 놀고, 맑은데 습도가 70% 이상이면 놀지 않습니다. 만약 비가 오고 바람이 불면 놀지 않고, 비가 오지만 바람이 안 불면 나가 놉니다.
이렇게 나무모양으로 도식화된 표를 보고 우리는 이 모델이 어떻게 값을 예측할지 명시적으로 알 수 있습니다. 이게 바로 DT 모델의 장점입니다.
그리고 이런 DT 모델을 여러 개 사용한 것이 바로 RT입니다.
나무가 여러개면 숲이니까 Tree가 여러 개라서 Forest라고 표현했다 라고 생각하면 이해하기 쉬워요~
데이터 준비하기
개발자의 시선이기 때문에 이론은 위에서 다 끝났습니다. ㅋㅋㅋㅋ 한 줄로 요약하면
"DT라는건 트리구조로 모델을 만드는 거구나~ RT는 그런 DT가 많은 거구나~ "
바로 Colab을 켭니다.
실습할 데이터와 Colab은 Github에서 다운받을 수 있습니다.
https://github.com/tkdlek11112/AI_by_dev
AI쪽 공부를 할 때 가장 중요한 건 데이터와 목적입니다.
어떤 데이터를 어떤 목적으로 사용하는지를 확실히 결정하고 진행해야 나중에 내가 뭐 때문에 이거 하고 있지? 라는 생각이 안 들어요.
이번에 우리가 진행할 학습의 목표는 "어떤 사람이 연체를 할까?" 입니다. 제공한 파일 중에 Description.txt를 열어보세요.
Data Set Information:
- 사용자의 대출 연체를 예측하는 문제
- 대표적인 불균형 분류 문제
- 개인의 금융거래, 보험, 통신 거래 내역 데이터를 사용
<X> AGE 연령 연속형
TOT_LOAN 대출 총액 연속형
TOT_LOAN_CRD 신용대출 총액 연속형
LOAN_BNK 은행권에서 발생한 대출 총액 연속형
LOAN_CPT 카드사/캐피탈에서 발생한 대출 총액 연속형
CRDT_CNT 신용카드 발급 수 연속형
GUARN_CNT 보증 건수 연속형
INCOME 소득 연속형
LOAN_CRD_CNT 신용대출 건수 연속형
LATE_RATE 보험료 연체율 연속형
LATE_RATE_1Y 최근 1년 보험료 연체율 연속형
INS_MON_MAX 월납입보험료 (최대값) 연속형
CANCEL_CNT_1Y 최근1년 실효해지건수 연속형
CALL_TIME 월별 통화시간 연속형
TEL_COST_MON 서비스 납부요금 연속형
MOBILE_PRICE 사용중인 핸드폰단말기 가격 연속형
SUSP_DAY 회선의 사용정지일수 연속형
LATE_TEL 핸드폰 요금 연체금액 연속형
COMB_COMM 결합상품가입 여부 이진형
SEX 성별: 남자(1), 여자(0) 이진형
PAY_METHOD(4) 핸드폰 요금 납부방법(B,C,D) 명목형(One-hot-encoding)
JOB(4) 직업군(B,C,D) 명목형(One-hot-encoding)
<Y> TARGET 대출연체여부: 미발생(0), 발생(1) 이진 (타겟변수)
이제 과몰입이 필요합니다. 내가 은행에서 일하고 있는데(혹은 대출업..) 대출서비스를 해주기 전에 이 고객이 연체를 할지 안 할지 미리 파악할 수 있다면 대출해줄지 말지 의사 결정하는데 도움이 되겠죠? 자 그럼 이제 우리는 <X>에 나열된 데이터를 가지고 대출 연체 여부를 예측하는 모델을 만들 겁니다.
그럼 한번 엑셀을 열어보세요. loan_data.csv
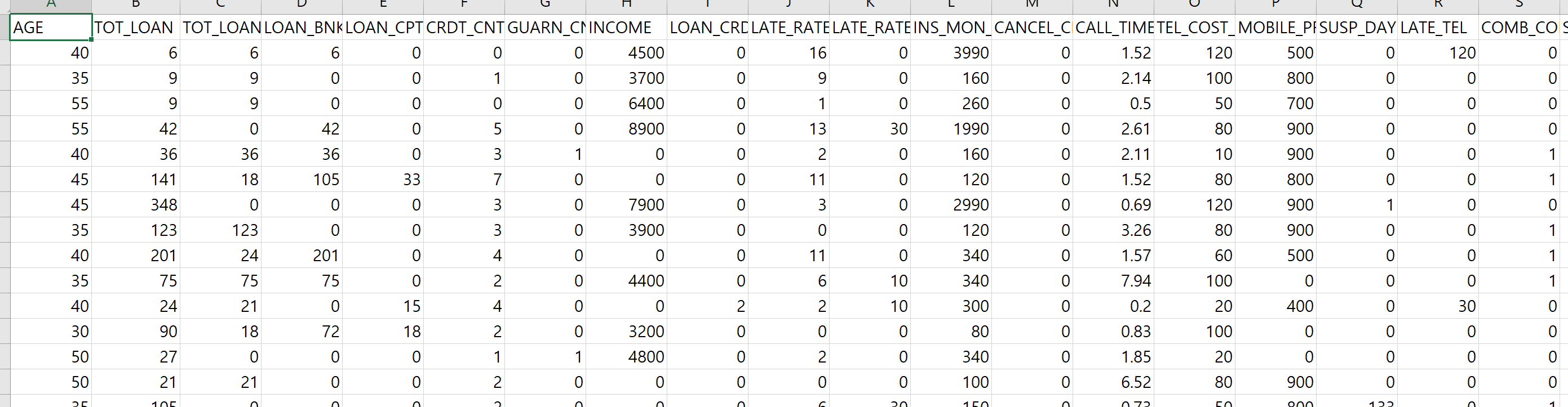
숫자가 무진장 많습니다. 세로로 개수를 세보면 한 4만 개가 있는데요, 샘플 데이터 치고는 생각보다 많은 양이네요. 엑셀 맨 오른쪽 칼럼을 보면 TARGET이라고 있습니다. 이게 0이면 대출 연체를 안 한 사람이고 1이면 연체한 사람이죠. 여기 4만 명에 대해서는 이미 연체를 했는지 안 했는지가 적혀있습니다. 이렇게 우리가 얻고자 하는 값을 Target값, y값이라고 부르고, 이런 값들을 포함한 데이터 셋을 "레이블링 된 데이터"라고 말합니다. 실제 업무에서는 Target값이 없이 <X> 값만 있어요. 사람이 일일이 체크해서 이 사람이 연체했는지 안 했는지 확인해서 0, 1 값을 채워야 모델로 학습할 수 있습니다. 이런 과정을 "레이블링"이라고 해요. (콩글리쉬로 라벨링이라고도 함) 이 데이터는 이미 레이블링 된 데이터셋이기 때문에 따로 레이블링 작업이 필요 없습니다.
자 그럼 구글 colab으로 넘어가서 새로운 페이지를 만듭니다. 하나씩 만들면서 해볼 건데 github에 풀버전이 있기 때문에 귀찮으시면 바로 다운로드하여서 실행만 하면 됩니다.
가장 먼저 할 건 데이터를 읽기 위해 Colab과 구글 드라이브를 연동하는 작업입니다.

위 코드를 실행하면 아래 링크가 뜨는데 링크를 눌러서 구글 로그인하면 Key값을 줍니다. 그 Key를 복사해서 빈칸에 입력하면 끝~

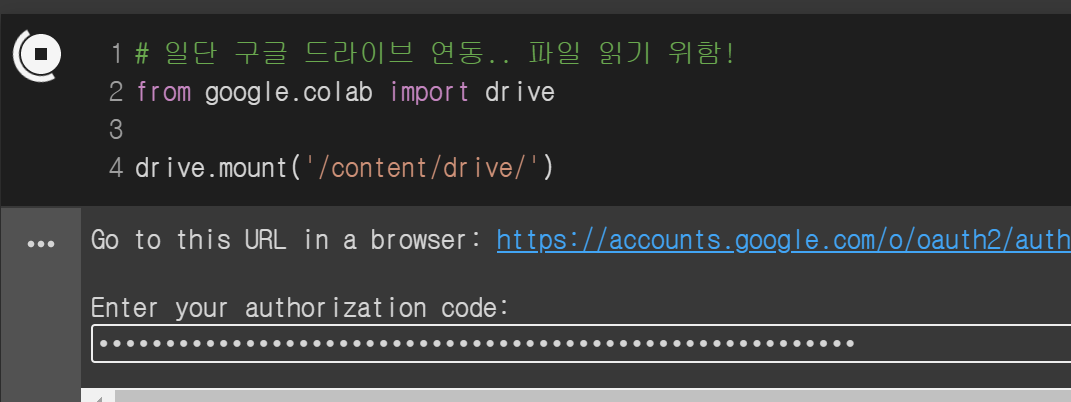
이렇게 구글 드라이브에 연동하면 /content/drive/경로에 내 구글 드라이브 파일이 보입니다. colab 왼쪽에 폴더 모양을 누르면 확인할 수 있습니다.

파일을 읽어올 때는 pandas로 읽어옵니다. pandas는 python에서 데이터를 엑셀처럼 관리할 수 있게 해주는 유용한 툴입니다. import os랑 import pandas를 해서 파일을 읽어올 수 있어요.
이제 데이터를 읽어왔는데요, 항상 데이터를 읽고 나서 코드를 작성할 때 데이터가 어떻게 생겨먹었는지 출력해보는 게 중요합니다. [2]를 보면 맨 아래줄에 data가 있는데 data를 출력하는 코드입니다. 그 아래 출력된 내용을 보면 데이터가 우리가 이전에 봤던 엑셀이랑 비슷한 모양인걸 알 수 있어요.
여기서 한 가지 중요점
데이터셋을 자세히 보면 숫자가 아니라 알파벳으로 표기되어있는 데이터가 있습니다. 바로 범주형 데이터들인데요. 다음과 같은 데이터가 범주형입니다.
성별(SEX) : M, F
지불방법(PAY_METHOD) : A, B, C, D
직업(JOB) : A, B, C, D
이런 범주형 데이터들은 약간의 전처리가 필요합니다. 처음 AI를 공부하시는 분들은 왜 바꿔줘야 하는지 이해를 못하는 경우가 많은데요... 아래 몇 가지 이유가 있습니다.
1. 모델이 학습을 하기 위해서는 데이터가 숫자로 표기되어야 한다.
2. 범주형 데이터는 학습에 방해가 된다.
2번이 상당히 중요합니다. 지금 데이터 셋은 다행히 범주형 데이터가 알파벳으로 저장되어 있어서 어떤 필드가 범주형 데이터인지 쉽게 구분이 가능합니다. 하지만 범주형인데 숫자로 표기돼있는 데이터셋도 있습니다. 예를 들어 지불방법이 A, B, C, D가 아니라 1, 2, 3, 4로 구분되어 있을 수 있죠. 그럼 숫자 데이 터니까 상관없네? 할 수도 있습니다.
근데 그게 아니라는 거죠. 데이터가 숫자가 아니라는 것은 모델 학습에 필요조건이긴 하지만 숫자라고 해서 범주형 데이터가 아니진 않습니다. (말이 어렵네..)
그럼 뭐가 범주형 데이터고 뭐가 아니냐? <--- 이거 AI 배울 때 10명 중 9명이 헷갈려함
이건 사실 직관력이 좀 필요한데요. 구분할 수 있느냐 없느냐로 생각하면 될 것 같아요. 성별 같은 경우 남자와 여자로 구분되기도 하지만 0과 1로도 구분할 수 있습니다. 숫자로 따지면 0과 1을 비교하면 1이 0보다 큰 건 당연하잖아요? 하지만 0과 1이 숫자의 의미를 갖는 것이 아니라 단지 남자와 여자를 구분하기 위해 쓰인 겁니다. 따라서 성별을 구분하기 위한 0과 1은 숫자로써 의미가 없습니다.
따라서 이렇게 숫자로써 의미가 없는 데이터를 모델한테 학습시켜 봤자 아~~~~무 도움 안된다는 거죠. 아시겠죠? ^^?
아무튼 이런 범주형 데이터들은 숫자로써 의미를 갖게 바꿔줘야 합니다. 어떻게 바꾸냐면 분류할 수 있는 개수만큼의 필드를 만들어서 0과 1로 구분하도록 만드는 것이죠. 예를 들면 성별은 남자와 여자 두 개로 구분할 수 있습니다. 따라서 남자 필드와 여자 필드를 추가해서 남자면 남자 필드 값은 1, 여자 필드 값은 0, 여자면 남자필드값은 0, 여자필드값은 1로 만들어주는 거죠. 코드에서 어떻게 구현되는지 볼까요?
먼저 범주형 데이터를 다 뽑아냅니다.
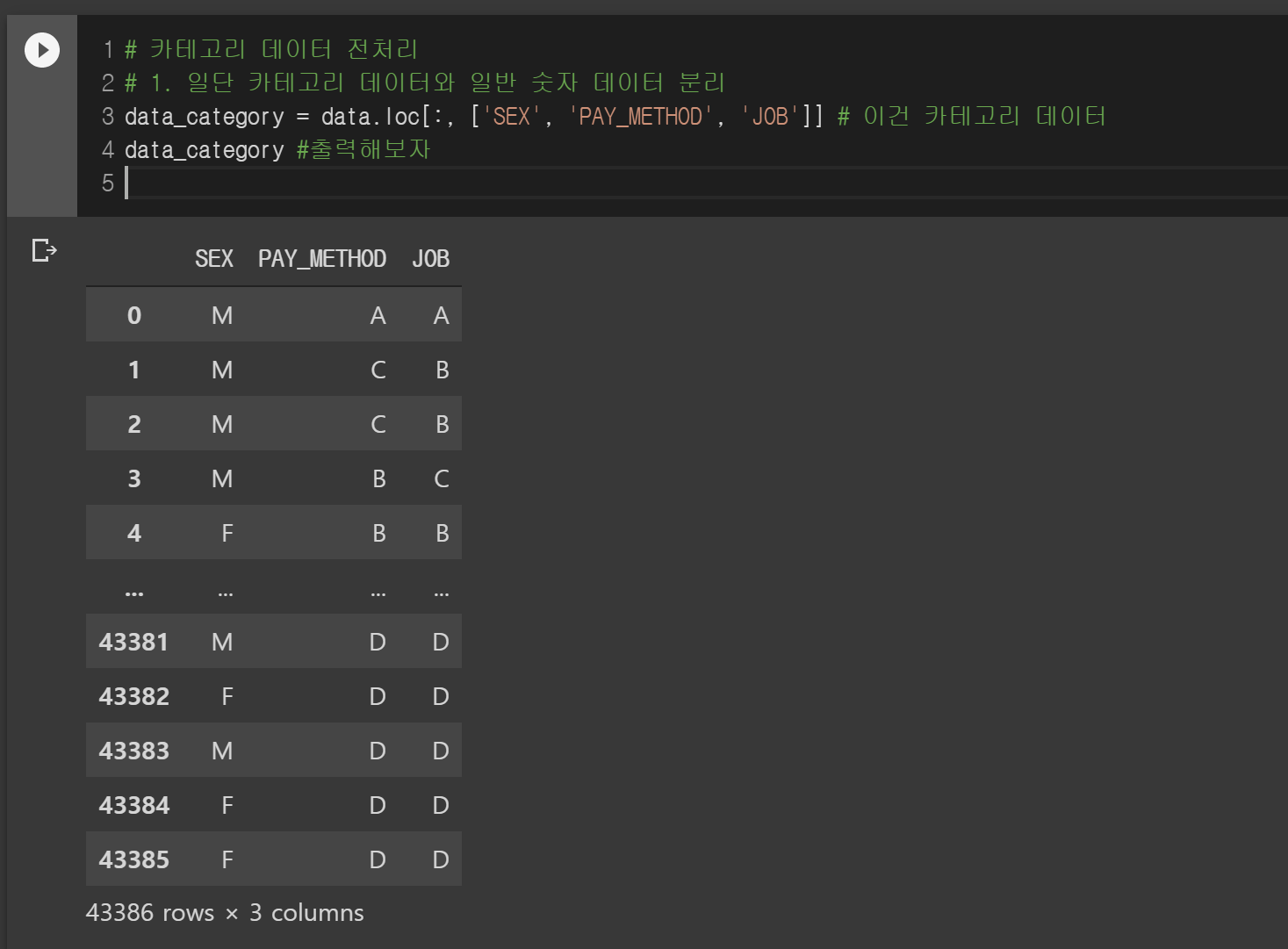
data에서 'SEX', 'PAY_METHOD', 'JOB' 필드를 뽑아내서 data_category에 넣었습니다. 이 data_category를 자동으로 전처리해주는 함수에 집어넣습니다.

그럼 알아서 더미 변수를 생성해서 만들어줍니다. 데이터로 보니 어떻게 변하는지 알겠죠?
여기서는 범주형 필드가 나타낼 수 있는 구분 값 만큼 필드를 만들어줬습니다. 예를 들어 성별이 남, 여 두가지로 구분되기 때문에 두개의 필드를 만들었습니다. 하지만 어떤 사람들은 범주형 필드를 전처리 할때 구분값 -1 개의 필드를 만들면 된다고 합니다. 왜냐하면 모든 필드가 0일때 하나의 상태를 나타낼 수 있기 때문이죠. 예를들어 A B C D 4개의 구분값을 같는 범주형 필드가 있다면 범주_A, 범주_B, 범주_C만 만들고 이 3개가 다 0일때는 D라고 생각하게 만드는 겁니다. 물론 모델에서 필드가 하나가 주는것은 성능향상에 도움을 주지만 이렇게 필드가 적을 때는 어떤 방법으로 하나 효과가 미미했습니다. (제 경험상) 그래서 이번엔 그냥 구분값 수만큼 필드를 만들어서 하겠습니다~
다시 돌아와서 더미 변수를 만들었으니 이 더미변수를 기존 <X>에 합쳐줍니다. <X>에 합칠 때 원본 범주형 필드는 빼고 합쳐야 합니다.

합치는 함수는 concat입니다. 엑셀에서 concatenate함수랑 동일한 역할을 합니다.
이제 data가 아니라 data_numeric을 이용해서 작업을 계속 진행합니다.
그다음 순서는 데이터 간에 상관도를 보기 위해 coolwarm차트를 그려봅니다.
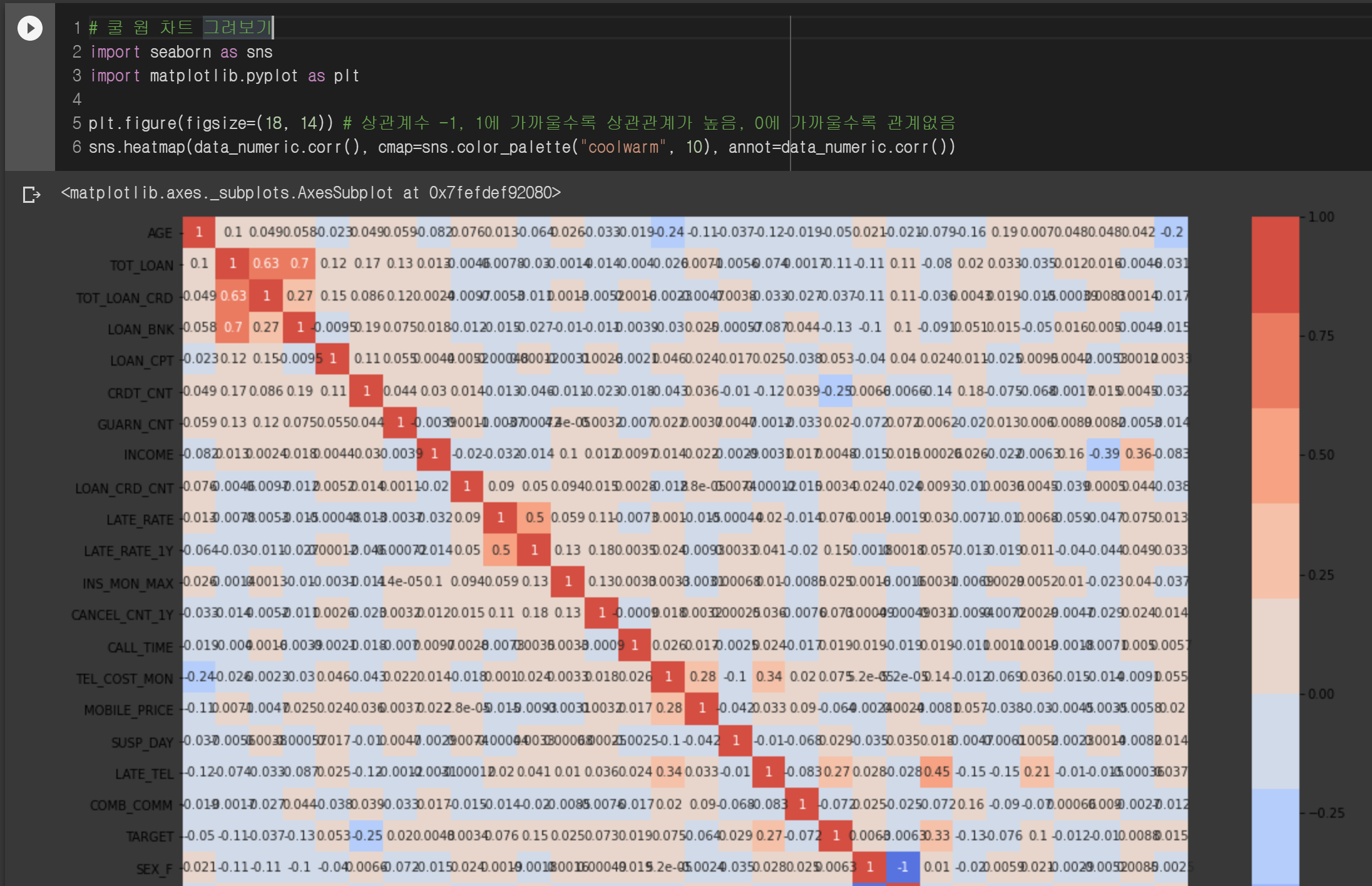
데이터 셋에 이미 TARGET값이 있기 때문에 TARGET값과 다른 변수들의 상관계수를 볼 수 있습니다.
TARGET값은 우리가 예측하기 위한 값이기 때문에 TARGET값과 상관도가 높은 변수들은 실질적으로 예측을 하는데 중요도가 높은 변수들입니다. 중요도가 낮은 변수들은 빼버려서 모델 성능을 높일 수 있습니다. 가로로 보든 세로로 보든 TARGET 줄을 한번 봅시다.
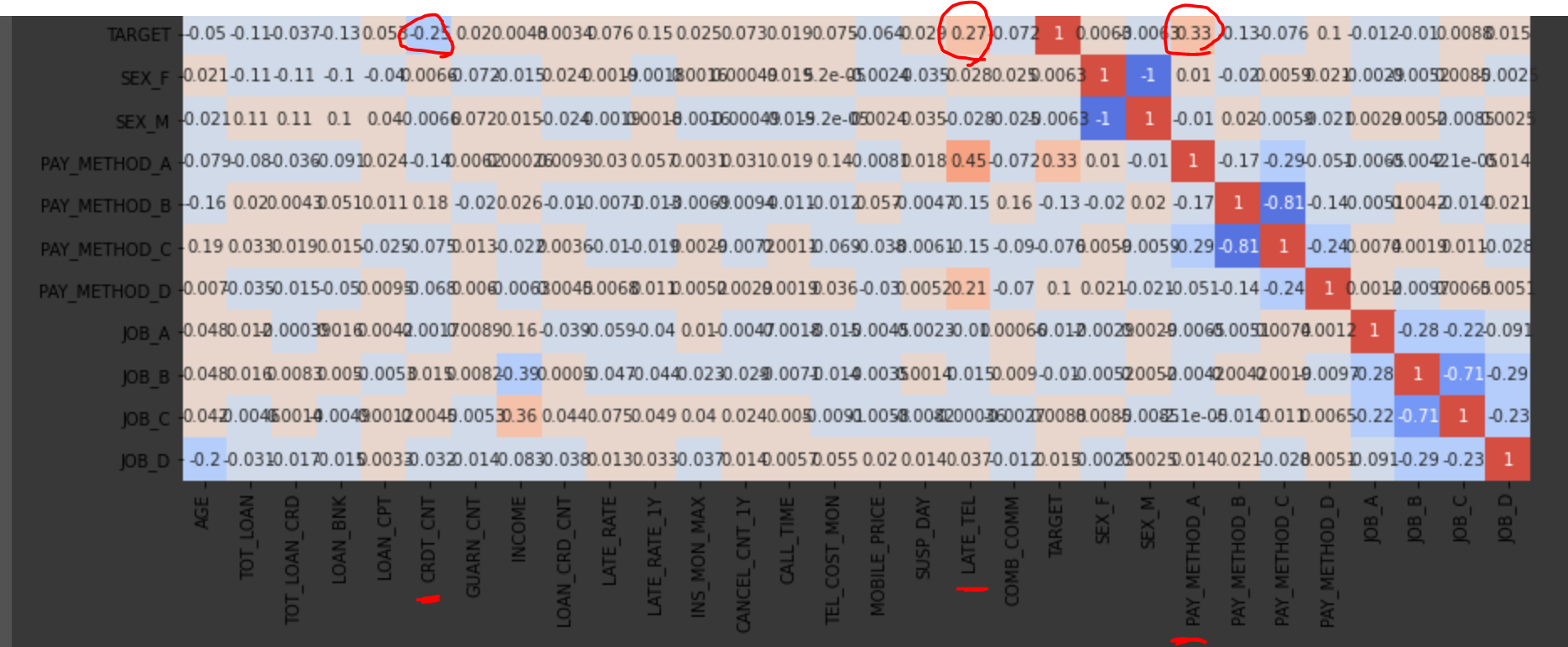
쓰윽 살펴보면 색이 진한 게 3개가 있는데 어떤 데이터인지 따라서 내려와 보면 CRDT_CNT와 LATE_TEL, PAY_METHOD_A입니다. 이 3 값이 뭐길래 TARGET과 상관계수가 높을까요?
CRDT_CNT는 신용카드 발급 수입니다. 상관계수가 -값인 거 보면 CRDT_CNT가 높을수록 TARGET이 0에 가깝다는 뜻입니다. 음.. 아마 신용카드를 많이 발급해서 돌려 막기를 하니까 연체가 적은 걸까요? ㅋㅋ 재미있는 데이터네요.
LATE_TEL은 핸드폰 요금 연체금액입니다. +값인 거 보니 LATE_TEL이 높을수록 TARGET이 1에 가깝다는 뜻입니다. 아무래도 핸드폰 요금을 연체하는 사람은 대출금도 연체하겠죠?
PAY_METHOD_A는 핸드폰 요금 납부방법 중에 하나인데, A방법으로 납부하는 사람들이 연체를 많이 하네요. A방법이 어떤 건지는 설명이 안되어있는데.. 아마 자동납부는 아니겠죠.
이렇게 대충 상관도가 높은 필드를 뽑을 수 있습니다. 나중에 한번 상관도가 높은 거만 따로 돌려보도록 하고 여기서는 알고만 하고 넘어갈게요~
이제 데이터에 대한 마지막 전처리 과정으로 학습(Train) 데이터와 테스트(Test) 데이터로 나누어 볼게요. 왜 학습이랑 테스트로 나누냐면.. 말 그.대.롭.니.다. 학습은 학습용이고 테스트는 테스트용이죠.
테스트를 할 때 학습에 사용한 데이터를 사용하면 모델이 알고 있는 데이터이기 때문에 정확도가 높게 나와 성능을 평가할 수 없습니다. 따라서 학습을 하지 않는 테스트 데이터를 나누고, 테스트 데이터에 대한 X값을 넣었을 때 모델이 예측한 Y값이 실제 테스트 데이터의 y값과 같은지 파악해서 성능을 평가하는 겁니다. 왜냐하면 우리는 테스트 데이터에 대한 TARGET값이 y값을 가지고 있으니까요 ^^

의사결정 나무 모델 만들기
이제 데이터는 준비가 끝났습니다. 학습용 X, y, 테스트용 X, y 4개만 있으면 됩니다.
먼저 의사결정나무 모델을 만들어 볼까요?
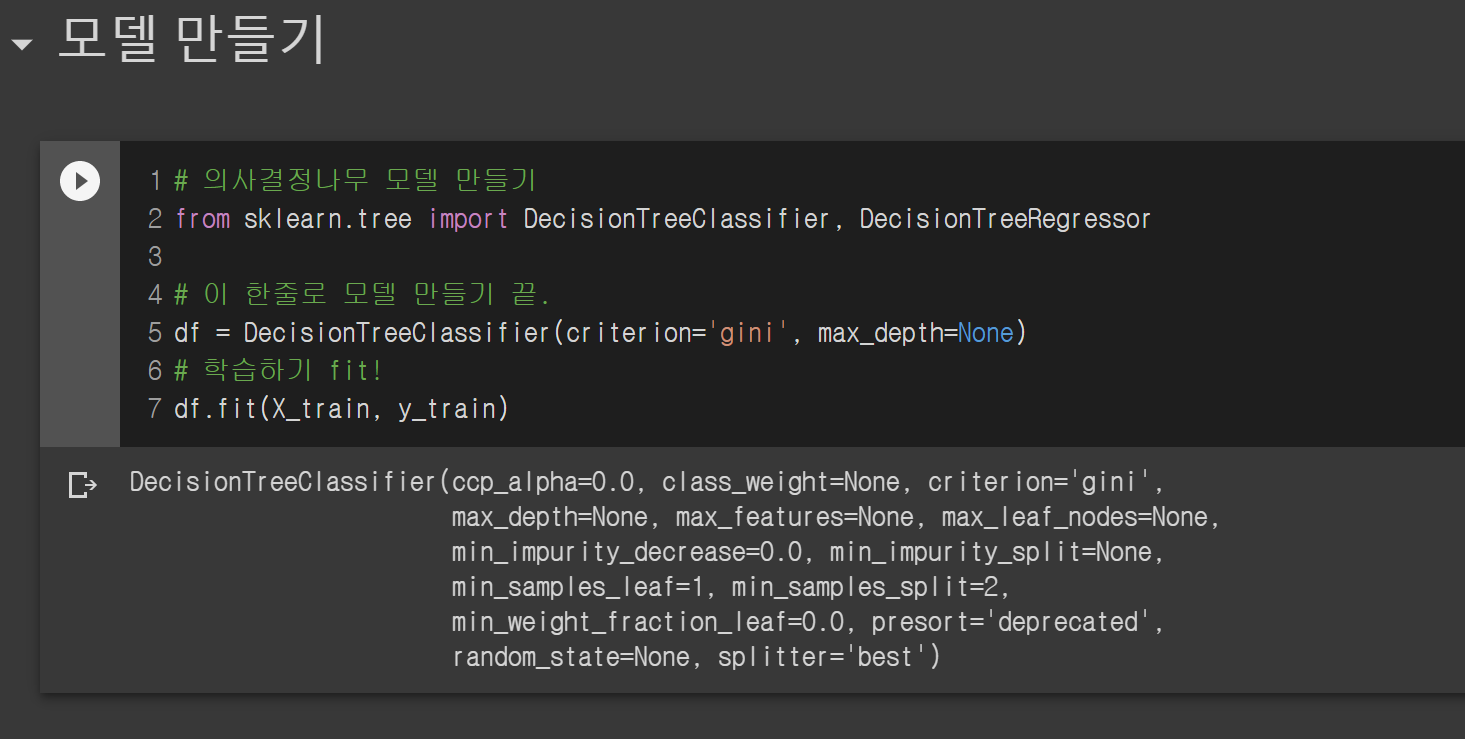
위에 엄청 열심히 데이터 준비하는 거에 비해 모델 만드는 거는 한방에 끝납니다. 허무..
df라는 모델을 DecisionTreeClassifier로 만들고 df.fit 하면 학습까지 완료됩니다.
이제 df라는 모델을 이용해서 예측을 할 수 있습니다. 그럼 테스트 데이터로 성능평가를 해볼까요?

성능 평가는 정확도(Accuracy)와 F1 Score로 진행했습니다. Train이 1.0으로 나오는 건 100% 정확도인데, 학습 데이터로 학습한 모델이 학습 데이터를 다시 예측하면 당연히 정답을 예측하겠죠? 반면 학습하지 않았던 테스트 데이터는 정확도가 0.89로 89%의 정확도를 보여줍니다.
대부분의 AI를 강의해주는 학원이나 인강에서는 이렇게 모델 성능만 측정하고 다음으로 넘어가게 됩니다. 근데 배우는 입장에서
"아니 모델 성능이 이렇게 나오는 게 뭐 어쨌다고?" 소리 나오거든요.
성능평가를 어떻게 한 거고 결과가 뭔지 모르기 때문이죠.
배우는 입장과 이 모델을 서비스에 적용하는 입장에서 제일 중요한 부분은 바로 predict입니다.

모델.predict를 하게 되면 입력된 값을 이용해 y값을 예측하게 됩니다. 여기서는 해당하는 사람의 신용카드 발급수나 핸드폰 연체료 등(X)을 이용해 그 사람이 연체를 할지 말지(y)를 예측하겠죠. 그래서 함수를 사용해서 출력해보면 0과 1 값으로 가득 찬 배열이 나옵니다. 이 배열이 의미하는 건 X에 들어있는 많은 사람들 각각이 연체를 할지 안 할지 예측한 값입니다.
따라서 이 예측한 값들 y_test_pred라고 정의한 값과 실제 y_test값이 똑같다면, 모델이 정확하게 예측한 것이고 다르면 예측 실패한 것이죠.
위에 성능평가에서 accuracy_score(y_test, y_test_pred) 함수가 바로 두 개를 비교해서 정확도를 산출해내는 함수입니다.
시각화해보기
앞서 DT의 장점은 데이터를 예측하는 데 사용했던 기준들을 "명시적으로 볼 수 있다"라고 언급했습니다. 그럼 한번 뿌려볼까요?

우리가 만든 트리가 너무 깊이가 깊어서 그림이 엄청 크게 나옵니다... ㅋㅋ
읽어보실 분은 읽어보세요...
랜덤 포레스트 모델 만들어보기
의사결정 나무 상위 호환인 랜덤 포레스트를 만들어보겠습니다. 사실 위 과정에서 하나만 바꿔주면 됩니다.

모델만 바꾸면 됩니다. df대신 rf라고 써주고.. 참 쉽죠?
아니 근데 Decision Tree인데 df라고 쓰고 있었네요 ㅋㅋㅋ
랜덤 포레스트가 의사결정나무보다 정확도가 3%정도 더 높네요. 아마 대부분의 트리 모델중에 랜덤포레스트가 제일 높을 겁니다. 검색해 보면 여러 트리 모델이 있는데 한 번씩 써보세요! (어차피 모델만 바꿔주면 되기 때문에 금방 합니다)
상관계수가 높은 값만 써볼까?
이전에 데이터를 분석할 때 상관계수가 높았던 3가지 값이 있었습니다. 그 3개만 가지고 모델을 만든다면 어떻게 될까요?
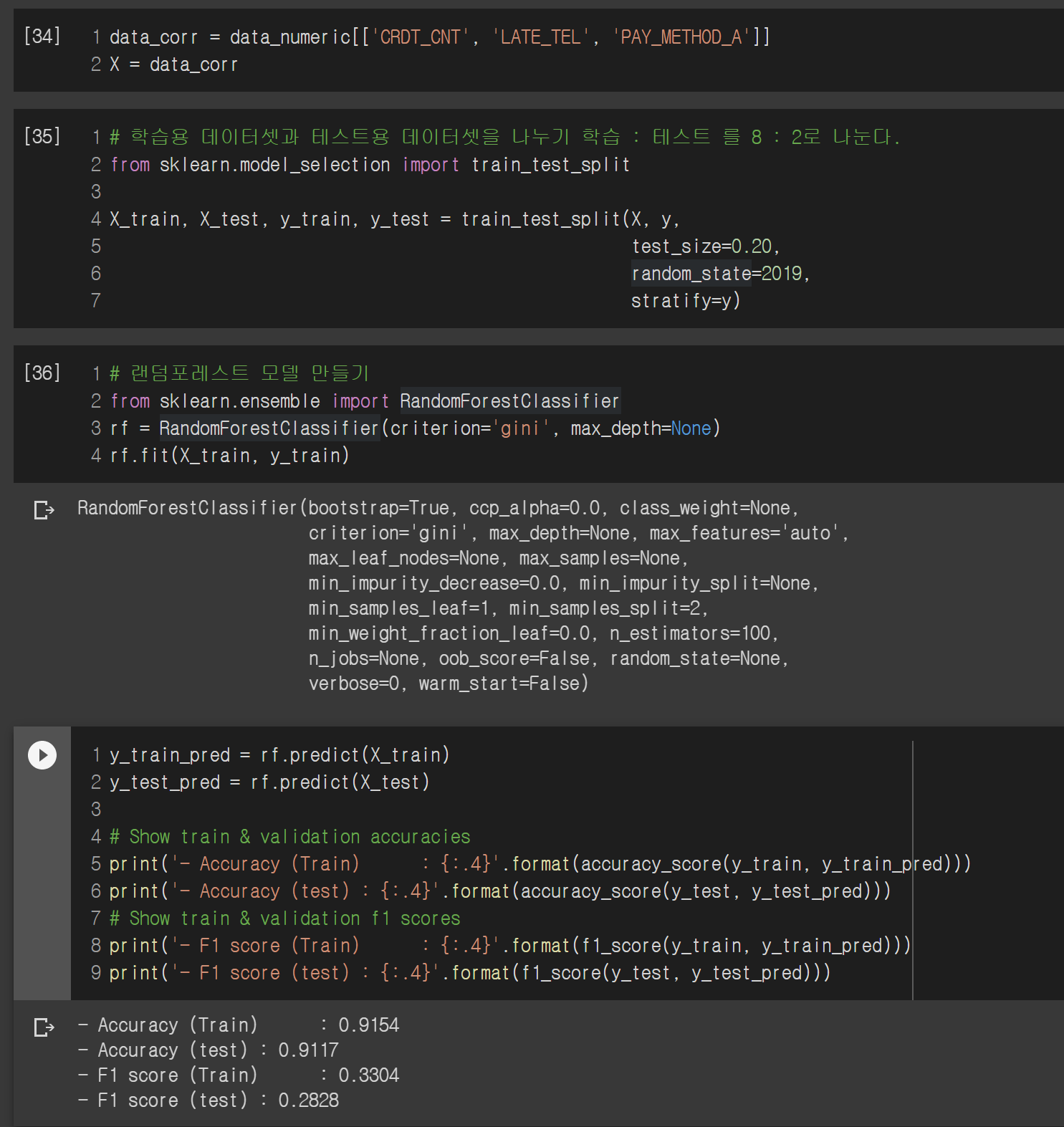
정확도는 비슷한데 F1 score가 많이 낮아졌습니다. 특이한 점은 학습 데이터에 대한 정확도가 100%가 아니네요. 아마 필드가 줄어들어서 정확한 예측을 하기 힘든가 봅니다.
어떤 필드를 써서 효율적으로 모델을 만드느냐.. 다 일일이 해보는 수밖에 없습니다. 이런 노가다가 AI 전문가분들이 하시는 일들이죠... 하루 종일 값 바꿔가면서 학습해보고 성능 뽑기 ^^
실제 서비스에는 어떻게 쓰일까?
의사결정 나무와 랜덤 포레스트로 분류 모델을 만들고 성능 측정까지 했습니다. 그럼 이 모델로 서비스를 어떻게 할까요?
쉽습니다. 모델.predict()를 쓰면 됩니다.
어차피 X값은 어디선가 받아올꺼자나요? 그 X값을 그냥 predict 하면 y값 나옵니다.
즉 모델을 만들어서 가지고 있으면, 데이터가 들어올 때마다 모델.predict(input)해서 나온 y값을 보여주면 됩니다.
물론 input값이 우리가 학습했던 데이터인 X와 똑같아야 합니다. row가 몇 개든 상관없지만 column의 수는 똑같아야지 모델이 제대로 예측하게 됩니다.
한번 가라 데이터를 만들어서 넣어볼까요?

위에서 사용하는 X값을 3개로 줄였으니 3개만 입력하면 됩니다. 신용카드 발급수와 핸드폰 요금 연체, 핸드폰 요금이죠.
X_input1을 넣었을 때는 대출 연체가 0이었는데 X_input2를 넣으니 대출연체가 1이 나오네요 ㅋㅋ 이런 식으로 서비스를 만들 수 있습니다.
마무리
이번 포스팅에서 의사결정 나무와 랜덤 포레스트로 분류작업을 해보았습니다. 사실 이 두 개의 모델이 분류로만 사용될 것 같지만 회귀로도 사용될 수 있습니다. 예를 들어 대출을 얼마나 받을지 값을 예측할 수 있죠. 전체적인 코딩 흐름은 변하지 않고 단순히 모델을 부를 때 DecisionTreeClassifier를 사용하는 게 아니라 DecisionTreeRegressor 사용하면 회귀가 됩니다. 복잡한 이론에 비해 사용법은 참 쉽죠?
이 두모델을 이용한 회귀는 다음번 예측하는 예제를 다룰 때 한 번씩 써먹어 보겠습니다.
다음 포스팅은 아마 PCA와 군집화가 될 것 같네요. 그때 회귀 예제를 해보길... ^오^
'Study > AI' 카테고리의 다른 글
| [개발자의 시선으로 보는 머신러닝 2-1편] 랜덤 포레스트로 예측, 분류 한번씩 해보기 (0) | 2020.07.13 |
|---|---|
| FAQ 챗봇 만들기 [4] - 실제 서비스 구현해보기 (3) | 2020.02.15 |
| 프로그래머즈 Dev-Matching - 머신러닝(자연어처리) 개발자 챌린지 해보기 (0) | 2020.02.01 |
| FAQ 챗봇 만들기 [3] - 많은 데이터로 실험해보기 (0) | 2019.11.22 |
| FAQ 챗봇 만들기 [2] - 모델다듬기 (0) | 2019.10.24 |