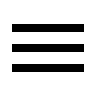
프로그래머즈 Dev-Matching - 머신러닝(자연어처리) 개발자 챌린지 해보기
- Study/AI
- 2020. 2. 1. 17:20
들어가기 전에
예전에 알고리즘 문제풀이만 제공했던 프로그래머즈라는 사이트가 채용 서비스를 지원하면서 이런 저런 과제를 제공해 과제 해결 능력을 보고 사람을 뽑는 채용 방법이 새로 생겼다. 최근 몇 개의 과제들을 살펴봤는데 서버쪽의 경우 대부분 API서버를 만들어서 제출하는 것이었고, 클라이언트의 경우 제공되는 API서버를 이용해 클라이언트 앱을 만들어 제출하면 된다. 과제 난이도는 그렇게 어렵지 않게 보였는데, 얼마나 지원하는지, 어떻게 채점하는지가 투명하지 않아 잘 모르겠다. ㅋㅋㅋ
이번에 머신러닝 채용 챌린지가 생겨서 신청해 봤는데 뭔가 문제가 어설프게 보이는 이유는 뭘까... 과연 이 문제를 누가 냈으며 과제 설명 페이지를 누가 만들었고 검토는 한건지 의문이 든다. 사실 돈을 내고 이용하는 서비스도 아니고, 일방적으로 지원자에게 채용 기회를 무료로 제공해주는 서비스라는 점에서는 품질이 떨어져도 감사하겠지만, 프로그래머스에 채용을 의뢰하는 기업 입장에서는 높은 품질의 서비스를 지원자에게 제공하는 것이 중요할 것이라고 생각된다. 뭐.. 너무 비지니스적인 입장으로 보지 말고, 그냥 문제나 풀어봐야겠다. ㅋㅋㅋㅋㅋ
시작하기
일단 2020.02.01일 부터 과제가 시작되었기 때문에 오늘 메일로 푸쉬가 와서 들어가 봤다. 과제의 내용은 HASHCODE라는 stackoverflow와 비슷한 서비스가 있는데, 거기에 올린 질문들이 어떤 질문인지 분류하는 문제이다. 훈련데이터를 2592개주고 500개의 테스트 데이터를 분류하여 제출하면 된다.
잠깐, 2592개라고??
텍스트에 대한 머신러닝을 할때 적어도 수만단위의 문장을 기준으로 학습해야 어느정도 정확한 데이터가 나온다. 그런데 2592개라니.. 너무 적은거 아닌가? ㅋㅋㅋ
사실 글이 2592개라는 것이지 글 하나하나 안에는 제목과 본문이 있기 때문에 하나의 글이 하나의 문장은 아닐것이다.
그래도... 너무 적은거 아니니?
아무튼 데이터나 한번 보자~ 하고 훈련데이터를 다운받봤다.

아닠ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ 맥에서 파일 만들었냐고요 ㅋㅋㅋㅋㅋ 인코딩 무엇...
윈도우에서 실행하니 글자가 깨져서 나온다... ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
하 디테일 무엇.. 프로그래머스야 돈받고 이거 하는건 아니라고 해줘.
그래도 파이썬에서 읽으면 잘 나오겠지... 한번 읽어보자.. ㅋㅋㅋ
코드는 간단하게 구글 colab에서 하기로 했다. (사실 내 윈도우컴에는 머신러닝, 자연어처리 패키지를 안받아놔서.. 일일이 설치하기 귀찮았다...)
호옴.. 엑셀로 읽으면 안되나봄... ㅋㅋㅋ colab에서는 잘읽히는거 보니 인코딩이 다른가보다.
흠 일단 빠르게 하기위해 본문은 스킵하고 타이틀만 읽어서 학습해보자.
가장 먼저 해볼 방법은 doc2vec으로 문장단위 임베딩하고, classfication 모델 아무거나 이용해서 분류해보는 방법이다. 제목을 보면 영어/한글/특수문자 가 섞여있는데, 이것들이 전부 label에 영향이 있다고 생각된다. 따라서 형태소 분석은 생략하고 stopword 처리만 해서 진행하려고 한다.
일단 그전에 1~5가 얼마나 분포되어있는지 살펴봐야겠다.
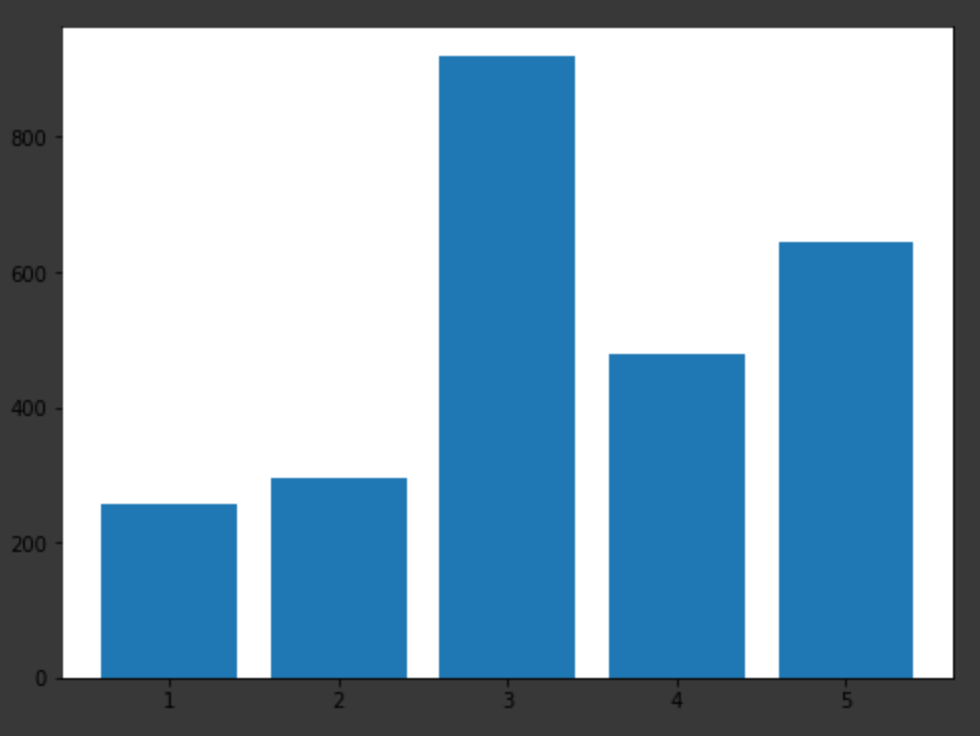
3이 좀 많다.
| title | 질문글의 제목 |
| content | 질문글 본문 |
| label | 질문글 분류 코드 (1: c, 2: c++, 3: java, 4: javascript, 5: python) |
설명을 보니 3번은 java다. 역시 java를 많이쓰는것인가. c에 대한 질문도 저정도면 많다고 생각된다. ㅋㅋ
다시 돌아가서 전처리를 해야하는데 일단은 띄어쓰기로 구분하기로 하고, "$$$" 텍스트를 제거하기로 했다. "$$$"이게 뭐냐면..

노골적인 키워드를 @@@로 가렸다는 주의사항을 홈페이지에서 확인할 수 있는데 데이터를 까보면 "$$$"로 치환되어있다. 진짜 일 똑바로 안하냐 ㅋㅋㅋㅋ

$$$를 제거하고 텍스트를 살펴보니 생각보다 대괄호가 많이 사용된것을 볼 수 있었다. 사실 코드에 대괄호는 리스트라는 것을 표기하기위해 사용되긴 하는데 여기서는 크게 의미가 있나? 싶다. 단지 문자열에서 강조하고 싶은 부분을 사람들이 대괄호로 감싸서 사용중인것을 확인했다. 따라서 대괄호도 없애버리기로 했다.
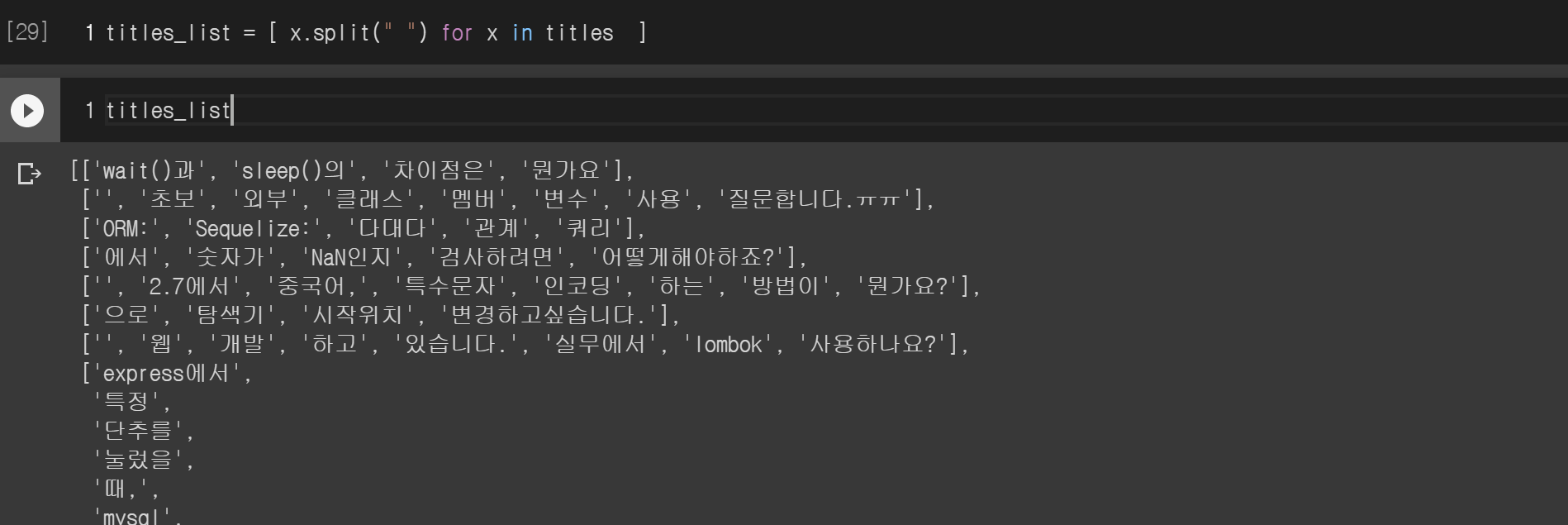
공백으로 split()했는데 흐흠.. 'wait()과'라는 요소는 'wait()'라고 표현되야 더 정확할것 같은데.. 그럴려면 형태소 분석을 해야하기 때문에 지금은 일단 무시하자.
모델만들기
모델은 doc2vec 임베딩 후 randomforestclassifier를 이용한 분류모델이다. 먼저 doc2vec으로 임베딩을 하자
임베딩 파라메터는 대충~~ 적정값을 입력했다. 사실 100차원 벡터가 크다고 생각되기는 하는데.. 데이턱터가 적으니 그냥 100 넣었다. 이제 랜덤포레스트 해보자.

랜덤포레스트는 더 간단하다. 대신 웨이트를 좀 줬는데 의미없을지도 모르지만 데이터가 불균형이라서 한번 맞춰줘봤다. 잘 안나오면 없애야지 ㅋㅋㅋ 이제 한번 돌려봐야겠다.
테스트해보기
이제 만든 모델을 이용해 테스트해보자. 먼저 테스트 데이터를 불러와서 학습할때와 같은 전처리를 해주고, 모델에 넣어준다. 주의할점은 임베딩할때 doc2vec.infer_vector를 이용해야한다는 점이다. fit을 하면 안된다.

이제 csv로 저장해서 업로드 해보자.. 두근두근

아니 27점 실화니 ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
대충했다곤 하지만 이건 아니지나.... ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
다시 제대로 해봐야겠다 ^^
************* 02.01 21:30
- 나이브베이지안으로 본문으로만 했더니 41점
************* 02.01 22:30
- LSTM으로 했더니 62점
************* 02.01 23:10
- 좀 더 했더니 71점

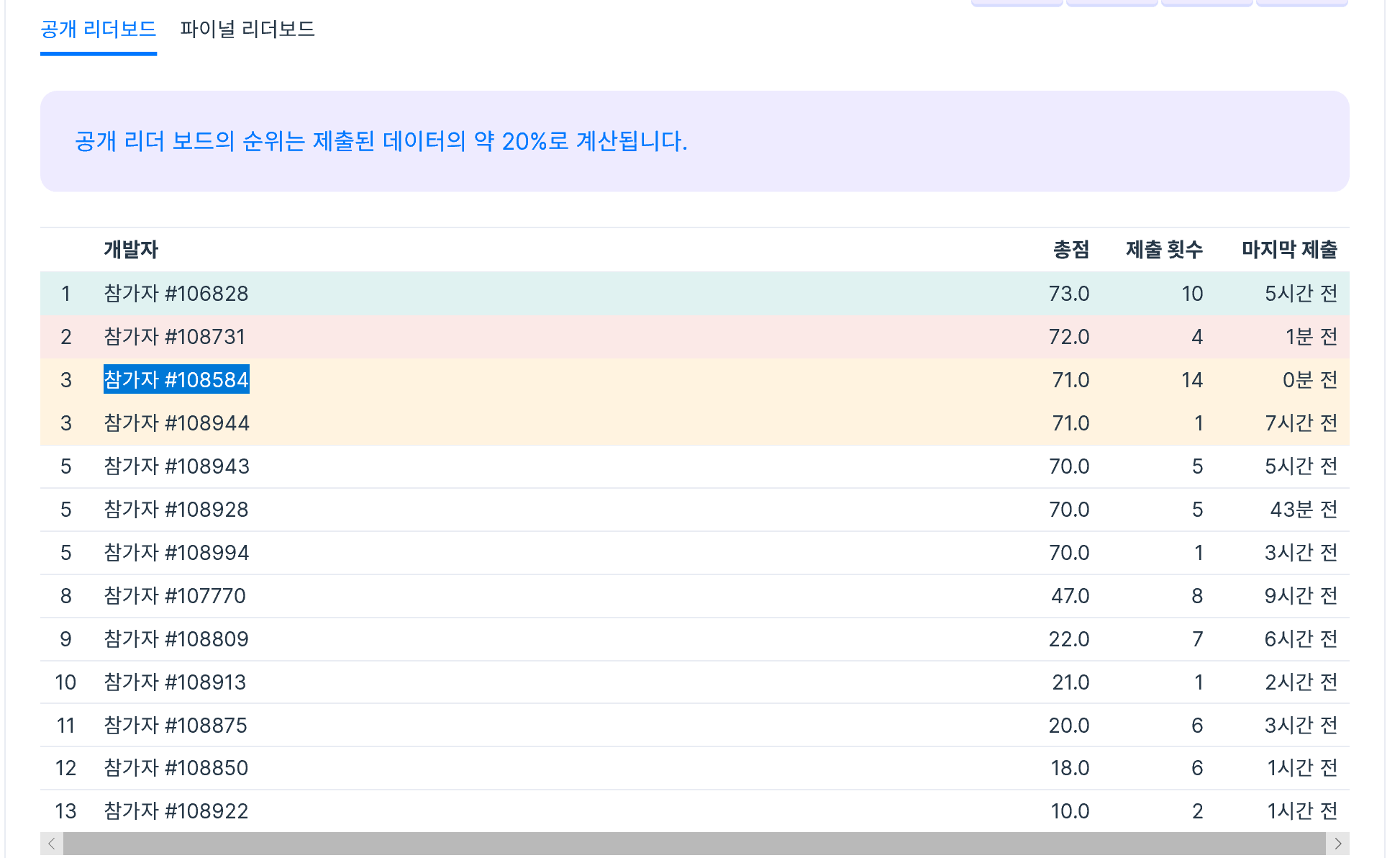
첫날이라 나름 상위권이다.
여기에 더이상 시간을 소비하는건 아까울것같아서 그만해야겠다.
'Study > AI' 카테고리의 다른 글
| [개발자의 시선으로 보는 머신러닝 2편] 의사결정나무, 랜덤포레스트를 이용한 분류 (1) | 2020.06.21 |
|---|---|
| FAQ 챗봇 만들기 [4] - 실제 서비스 구현해보기 (3) | 2020.02.15 |
| FAQ 챗봇 만들기 [3] - 많은 데이터로 실험해보기 (0) | 2019.11.22 |
| FAQ 챗봇 만들기 [2] - 모델다듬기 (0) | 2019.10.24 |
| FAQ 챗봇 만들기 [1] - 모델만들기 (2) | 2019.10.22 |