FAQ 챗봇 만들기 [1] - 모델만들기
- Study/AI
- 2019. 10. 22. 00:04
요즘 챗봇이 대세이기는 한데, 실제로 일상적인 대화를 하는 챗봇보다는 뚜렷한 목적을 가진 챗봇이 업무에서 더 많이 사용되는 것 같아요. 물론 일상적인 대화도 되고 특정 목적에도 적합한 완벽한(?) 챗봇이 있다면 좋겠지만 아직 AI 기술이 거기까지는 안될 것 같습니다. ㅎㅎㅎ아무튼 이번에는 FAQ 챗봇을 만들어 볼 건데, 회사에서 진행했던 프로젝트를 기반으로 처음부터 시작합니다!
목차
-- 2019/10/08 FAQ 챗봇 만들기 [1] - 모델만들기
github - https://github.com/tkdlek11112/faq_chatbot_learning
유튜브 - https://youtu.be/q9D8jd2723w
FAQ 챗봇 쉽게 만들어보기!
doc2vec를 이용해 FAQ 기능을 하는 챗봇을 만들어 보겠습니다. 질문과 답변 세트 데이터가 있으면 doc2vec 모델로 학습후 사용자가 어떤 질문을 하면 가장 비슷한 질문을 찾아서 답하는 구조입니다. 속성 정리글 : https://cholol.tistory.com/466 소스 Github : https://github.com/tkdlek11112/faq_chatbot_learning
www.youtube.com
▷ 목표
일단 목표는 FAQ 데이터를 읽어서 모델을 만드는 프로그램과 실제로 질문을 하고 답변을 할 수 있는 간단한 채팅 시스템. 그리고 질문과 답변을 관리할 수 있는 관리자 페이지를 만드는 겁니다. 말로 하니까 왠지 간단해 보이네요... ㅋㅋ
▷ 데이터 만들기
그럼 가장 먼저 FAQ 데이터를 읽어서 학습하는 모델을 만들어보겠습니다. 여기서 모델이란 doc2vec을 이용해서 FAQ데이터들의 질문들을 벡터화 하는 과정인데요. word2vec은 아마 들어보셨을겁니다. 단어를 벡터화 하는 것이지요. 처음 들어보시는 분들은 구글링 한번 해보시면 금방 이해하실 수 있습니다. doc2vec은 단어가 아니라 문서를 기준으로 (여기서는 문장) 벡터를 만드는 라이브러리입니다. doc2vec을 사용하면 서로다른 문서들이 같은 차원의 벡터값을 갖게됩니다. 각 문서가 갖는 벡터값을 비교해 같으면 같을수록 유사한 문서라는 것을 알 수 있습니다.
따라서 doc2vec을 이용해 FAQ의 질문들을 벡터화한다면, 어떤 질문이 들어왔을 때 동일 모델로 질문을 벡터화한 다음, 저장돼있는 질문들의 벡터와 비교해서 가장 유사한 질문을 찾을 수 있습니다. 가장 유사한 질문을 찾은 다음, 그 질문의 답을 출력하면 FAQ챗봇을 만들 수 있습니다.
모델을 만들기 위해 코딩을 시작해봅시다. 코딩은 구글 colab으로 진행해볼게요. 많은 사람들이 아시는 주피터 노트북과 비슷한 기능을 가상 머신과 함께 제공해주는 구글의 서비스입니다. GPU까지 제공해주기 때문에 컴퓨터가 안 좋은 사람들도 충분히 학습을 돌릴 수 있어요. 구글 드라이브에서 실행할 수 있습니다~!

만약 더보기에 없다면, 연결할 앱 더보기에서 Google Colaboratory를 찾은 다음 연결하면 나타납니다.
모델을 만들기 전에 일단 데이터가 있어야겠죠? 여기서는 샘플로 5개의 질의응답만 만들어보겠습니다.

위와 같이 5개의 FAQ데이터를 임의로 만들었습니다. 이제 여기 5개의 질문을 벡터화할 건데요, 사실 벡터화할 때 데이터는 많아야 좋습니다. 이렇게 적으면 서로 간에 구분이 잘 안될 수 도 있거든요. 근데 일단은~ 예시니까 5개로 해보겠습니다.
▷ 형태소 분석
doc2vec으로 문장을 벡터화하기 전에 약간의 전처리 과정이 필요합니다. 일단 각 문장을 tokenize(토큰화) 해야 합니다. 토큰 화하는 과정이 영어랑 한국어랑 조금 다른데, 한국어의 경우 형태소 분석(pos tagging)을 통해 형태소 단위로 나눈 뒤, 토큰으로 사용할 형태소를 결정하고 나눕니다. 즉 각 문장을 형태소 단위의 배열로 만듭니다.
한국어 형태소 분석기는 여러 가지가 있는데 여기서는 꼬꼬마 형태소 분석기를 사용하겠습니다.
일단 시작하기 전에 colab에 konlpy 패키지를 설치합니다. konlpy는 한국어 자연어 처리를 위한 패키지인데요, 아쉽게도 colab에 기본적으로 설치되어있지 않아서 매번 설치해줘야 합니다. 칫 - -

colab에서 !를 앞에 붙이면 명령어를 사용할 수 있습니다. !pip install konlpy로 패키지를 설치합니다!

설치한 패키지에서 Kkma를 import 하고 jpype도 import 합니다. jpype는 파이썬에서 자바를 사용할 수 있게 해주는 패키지인데, 기본적으로 kkma가 자바 베이스라서 꼭 필요합니다. Kkma()로 형태소 분석기를 불러온 다음 kkma.pos(doc)로 형태소 분석을 진행합니다. '/'.join(word)부분은 형태소 분석한 단어와 형태소명을 '단어/형태소'형태로 출력하기 위한 코드입니다. attatchTreadToJVM()은 앞에서 언급했던 것처럼 자바를 사용하기 위한 소스코드입니다.
이렇게 tokenize_kkma 함수를 만들었으니 1번 문장을 형태소 분석해볼까요?

형태소 분석을 하면 문장이 단어/형태소 형태의 배열로 출력됩니다. 1번 문장은 총 10개의 형태소로 나뉘었네요. 형태소 분석기 종류에 따라 결과가 조금씩 다를 수 있기 때문에 어떤 형태소 분석기를 사용하는지에 따라 결과가 달라질 수 있습니다. 저는 kkma를 사용했는데, 그 밖에도 한국어 형태소 분석기가 많기 때문에 한번 돌아가면서 사용해 보세요~! Okt나 트위터, 최근에 나온 카카오 형태소 분석기도 있습니다~!
▷ Doc2Vec 모델 만들기
Doc2Vec을 이용해 모델을 만들기 위해서는 토큰화 된 리스트와 태그 값이 필요합니다. 여기서 태그 값은 뭐 특별한 게 아니고 문장 번호라고 생각하시면 됩니다. [ 문장의 번호, 문장을 토큰화한 배열 ] 이렇게 두 개의 값을 가진 리스트를 사용해 doc2vec 모델을 만들 수 있습니다. 실제로 모델을 만드는 데 사용하는 건 토큰 값이지만, 비슷한 문장이 무엇인지 찾기 위한 인덱스로 태그 값을 사용하게 됩니다.

TaggedDocument function을 사용하면 Doc2Vec에서 사용할 수 있는 태그 된 문서 형식으로 변경됩니다. 출력해보면 words배열과 tags값을 갖는 Dic형태의 자료형이 되었음을 확인할 수 있습니다. 이제 모델을 만들어봅시다. 사실 데이터가 5개밖에 없기 때문에 아주 엉터리 모델이 나올 겁니다. ㅋㅋ

doc2vec 모델을 만들 때 파라미터는 여러 가지가 들어가는데, 저는 보통 vector_size와 min_count정도를 수정합니다. vector_size는 만들어지는 벡터의 차원 크기이고, min_count는 최소 몇 번 이상 나온 단어에 대해 학습할지 정하는 파라미터입니다. 여기서는 일단 사이즈 50에 최소 횟수는 1로 지정했습니다. epoch는 10번으로 해서 train 시켰습니다.
▷ 유사 문장 찾기
이제 이 모델로 어떤 문장이 들어왔을 때 1~5번 중에 무엇과 비슷한지 알아보겠습니다. 먼저 어떤 문장이 들어오면 그 문장을 벡터화하고, 그 벡터가 어떤 문장과 비슷한지 태그 값을 찾아보도록 하겠습니다.

과연 제대로 됐는지 확인하기 위해 1번 문장을 그대로 쳤는데.. 이럴 수가!?! 전혀 다른 답이 나오네요. ㅡ ㅁ ㅡ ? 이 문장과 가장 비슷한 상위 2개를 끄집어냈는데 4번과 3번이라니... 아?
테스트할 문장을 벡터화할 때도 형태소 분석을 해줘야 합니다. 왜냐면 저희가 모델을 학습할 때 문장들을 형태소 분석해서 넣어줬잖아요? ㅎㅎ 두 개를 맞춰줘야죠. 다시 한번 해보겠습니다.
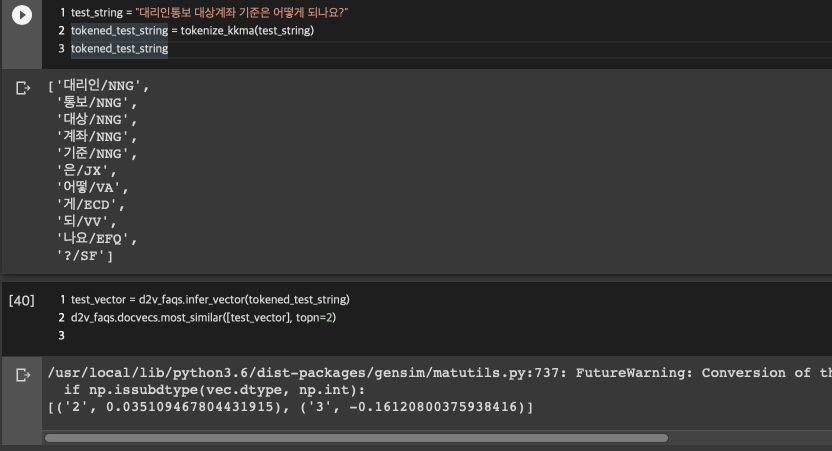
이번엔 2번 문장을 형태소 분석 후 넣어보았습니다. 똑같이 상위 2개인 topn=2로 뽑았더니!? 그래도 이번엔 2번이 나왔네요! 하지만 유사도가... 0.03이라니...
doc2vec이라는 모델은 문서 단위로 벡터화하는 것이기 때문에 문서가 많아야 합니다. 여기서는 문장이겠죠? 문장이 많으면 많을수록 문장 간의 거리를 계산해서 더 잘 구분해 줍니다. 간단하게 생각하면 문장이 적으면 적중률이 높을 것 같은데 사실은 그 반대인 것이죠. 데이터가 많을수록 그 데이터 간의 차이를 구분할 수 있기 때문에 더 잘 예측하게 됩니다. 지금은 문장이 5개 바께 없어서 벡터가 아주 삐쭉빼죽 제멋대로 일거예요. 그럼 우선 데이터를 더 꽉 채울 필요가 있겠군요!
다음 포스팅에서는 데이터를 늘리고 모델의 성능을 어떻게 더 끌어올릴 수 있는지에 대해 얘기해보겠습니다~
'Study > AI' 카테고리의 다른 글
| 프로그래머즈 Dev-Matching - 머신러닝(자연어처리) 개발자 챌린지 해보기 (0) | 2020.02.01 |
|---|---|
| FAQ 챗봇 만들기 [3] - 많은 데이터로 실험해보기 (0) | 2019.11.22 |
| FAQ 챗봇 만들기 [2] - 모델다듬기 (0) | 2019.10.24 |
| 문자열 데이터 CNN vs RNN 어떤 모델이 더 좋을까? (0) | 2019.08.07 |
| [머신러닝 무작정 따라하기] 1.머신러닝 시작하기 ~ 이진 분류기 만들기 (0) | 2018.09.10 |